 Java并发容器和框架
Java并发容器和框架
# 1. ConcurrentHashMap
# 1.1 为什么使用?
- 线程不安全的HashMap
HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形,Entry的next节点永不为空,就会产生死循环获取Entry - 效率低下的HashTable
HashTable使用synchronized保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问时,就会进入阻塞或轮询状态 - ConcurrentHashMap
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是因为所有访问HashTable的线程都必须竞争同一把锁,假如容器有多把锁,每一把锁用于锁定容器其中一部分数据,那么当多线程访问容器内不同数据段的数据时,线程间就不存在锁竞争,从而有效提升并发访问效率,这就是ConcurrentHashMap的锁分段技术。
ConcurrentHashMap锁分段技术可有效提升并发访问率
# 1.2 ConcurrentHashMap的结构
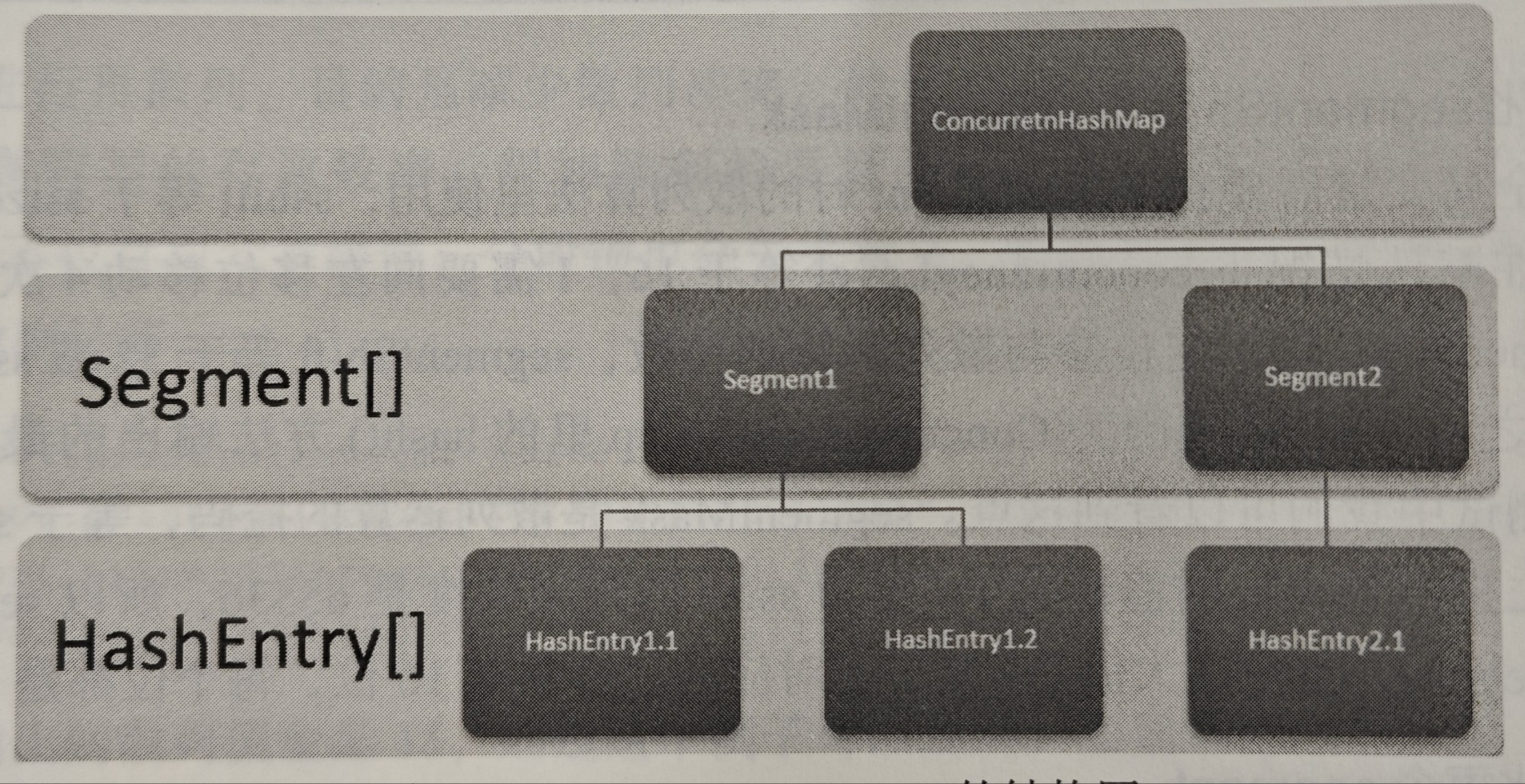 ConcurrentHashMap由Segment数据结构和HashEntry数据结构组成。Segment是一种可重入锁,在ConcurrentHashMap中扮演锁的角色;HashEntry则用于存储键值对数据。
ConcurrentHashMap由Segment数据结构和HashEntry数据结构组成。Segment是一种可重入锁,在ConcurrentHashMap中扮演锁的角色;HashEntry则用于存储键值对数据。
一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap相似,是一种数据和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数据的数据进行修改时,必须首先获得与它对应的Segment锁
# 1.3 ConcurrentHashMap的操作
- get操作
先经过一次散列运算,使用这个散列值通过散列运算定位到Segment,在通过散列算法定位到元素
public V get(Object key){
int hash = hash(key.hashCode());
return segmentFor(hash).get(key,hash);
}
2
3
4
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空才会加锁重读。我们知道 HashTable容器的get方法是需要加锁的
那么ConcurrentHashMap 的get操作是如何做到不加锁的呢?
原因是它的get方法里将要使用的共享变量都定义成volatile类型,例如用于统计当前Segement大小的count字段和用于存储值的HashEntry的 value。定义成volatle的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值, 但是只能被单线程写(有一种情况可以被多线程写,就是写人的值不依赖于原值),在get操里只需要读不需要写共享变量count和 value,所以可以不加锁。
之所以不会读到过期的值,是因为根据Java内存模型的 happens before原则,对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取 volatile变量,get操作也能拿到最新值
- put操作 由于put方法需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须加锁
- 第一步先定位到某一个Segment
- 第二步判断是否需要对Segment里的HashEntry数组进行扩容
- 第三步定位添加元素的位置,然后将其放在HashEntry数组里
Segment是在插入元素之前判断HashEntry是否到达容量,而HashMap是插入之后再判断,扩容是创建一个容量是原来两倍的数组,只针对具体某一个Segment扩容
- size操作
多线程场景是否可以通过累加所有Segment里的count即可呢?
虽然Segment的全局变量count是一个volatile变量,记录了元素数量,但是在多线程环境中,在对多个Segment的count累加时,之前累加的count可能已经发生了变化,所以会有误差。如果对所有Segment的put,remove,clean方法全部锁住,又非常低效
但实际上在累加count操作过程中,之前累加过的count发生变化几率非常小
所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小
那么ConcurrentHashMap是如何判断在统计过程中容器是否发生了变化?
使用 modCount变量,在put,remove,clean方法里操作元素前都会将变量modCount进行加一,那么在统计size前后比较modCount是否发生了变化,从而得知容器是否发生变化
# 2. ConcurrentLinkedQueue
在并发编程中,有时需要使用线程安全的队列,如果要实现一个线程安全的队列有两种方式:
- 阻塞算法 使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)
- 非阻塞算法:使用循环CAS操作实现
笔记
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,采用先进先出的规则对节点进行排序,采用“wait-free”算法(即CAS算法)实现
# 2.1 入队过程
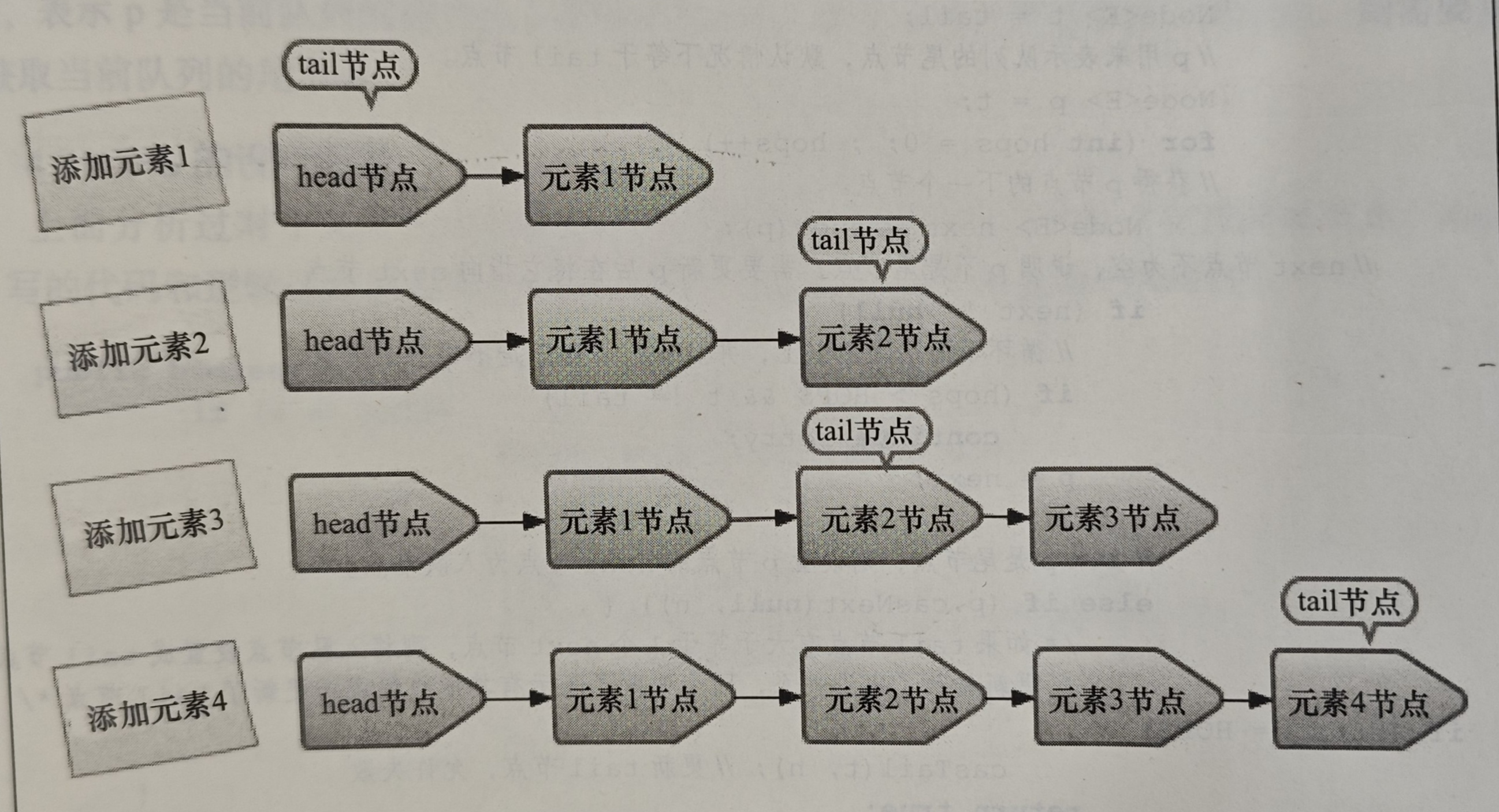
- 将入队节点设置为当前队列尾节点的下一个节点
- 更新tail节点:若tail节点的next节点不为空,则将入队节点设置为tail节点;若为空,则将入队节点设置成tail节点的next节点,所以tail节点不总是尾节点
减少CAS更新tail节点的次数,从而提高入队的效率
# 2.2 出队过程
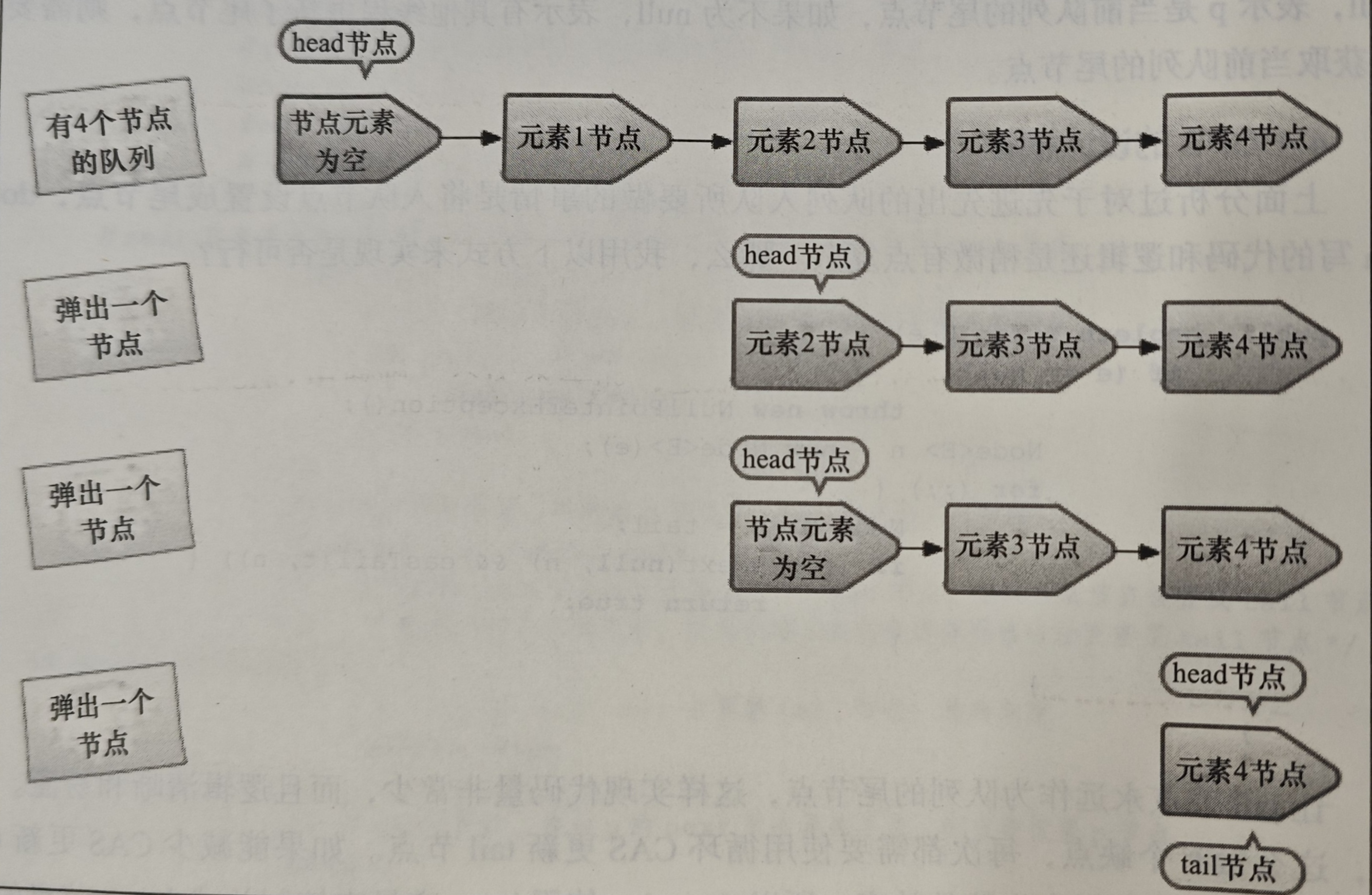
- 当head节点里有元素时,直接弹出head节点的元素,而不会更新head节点
- 当head节点里没有元素时,出队操作才会更新head节点
减少使用CAS更新head节点的消耗,从而提高出队效率
# 3. 阻塞队列
# 3.1 定义
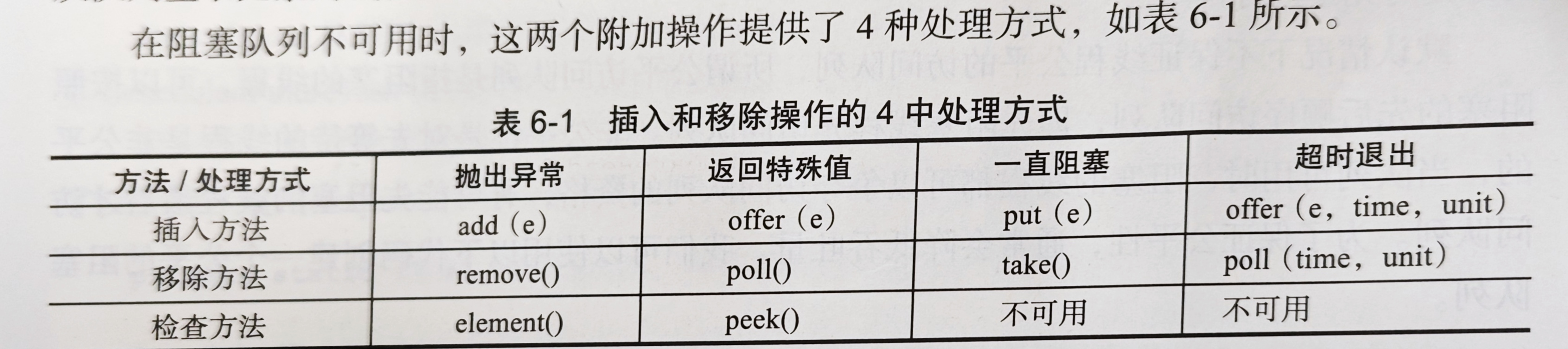
阻塞队列是一个支持两个附加操作的队列。这两个附加的操作支持阻塞的插入和移除方法,常用于生产者和消费者的场景。
- 支持阻塞的插入方法:当队列满时,队列会阻塞插入元素的线程,直到队列不满
- 支持阻塞的移除方法:在队列为空时,获取元素的线程会等待队列变为非空
# 3.2 Java里的阻塞队列
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列,FIFO(元素排序规则),默认情况不保证线程公平的访问队列,有可能先阻塞的线程最后访问队列,所以使用可重入锁保证访问者的公平性
- LinkedBlockingQueue:一个由链表结构组成的无界阻塞队列,FIFO
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列,自定义Compare方法指定元素排序规则,不再是FIFO
- DelayQueue:一个使用优先级队列(PriorityQueue)实现的无界阻塞队列,支持延时获取元素,可用于实现保存缓存元素的有效期或者定时任务调度
- SynchronousQueue:一个不存储元素的阻塞队列,每一个put操作必须等待一个take操作,否则不能继续添加元素,支持公平性访问队列,默认都是非公平策略
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列,transfer方法实现如果此时有消费者正在等待接收元素,可以直接把生产者传入的元素立刻传输给消费者,不用存入队列,如果没有消费者,则存入tail节点
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列,可以减少多线程的竞争
# 4. Fork/Join框架
# 4.1 定义
Fork/Join框架是一个Java7提供的用于执行并行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
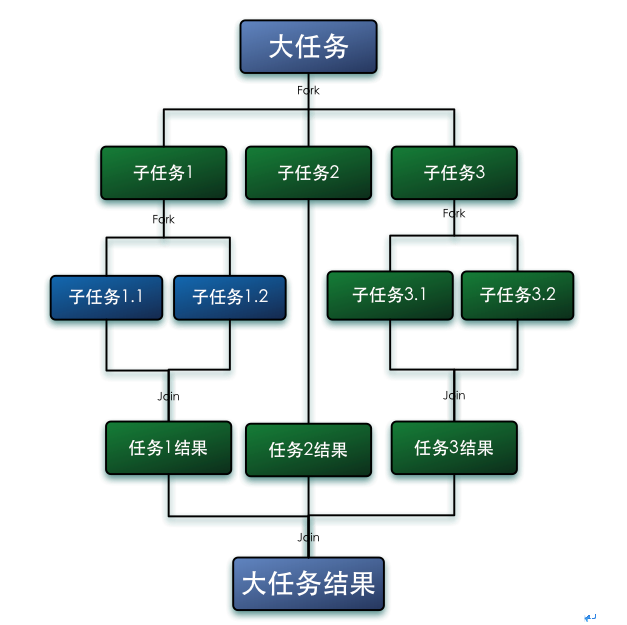
# 4.2 工作窃取算法
笔记
工作窃取算法是指某个线程从其他队列里窃取任务来执行
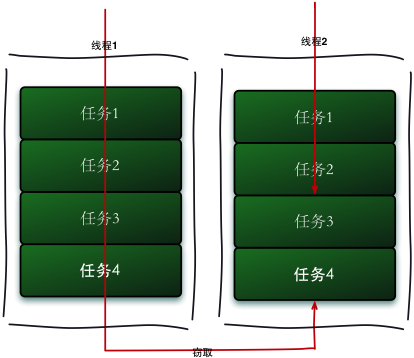
那么为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如 A 线程负责处理 A 队列里的任务。
但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。
而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。