 Bean生命周期
Bean生命周期
提示
本文主要描述xml文件创建bean以及加载到IOC容器中的全部流程
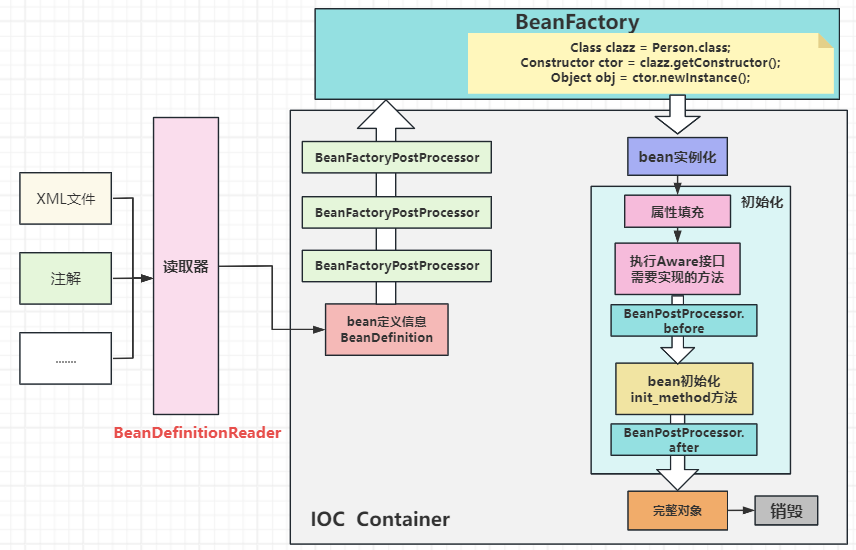
# 1. Bean的创建方式
使用Spring XML文件方式配置:在XML配置文件中,使用<bean> 标签来定义Bean
使用注解( javaweb):可以使用@Component、@Service、@Controller、@Repository等注解来定义Bean
@ComponentScan用于扫描指定包下的所有使用@Component定义的Bean
使用 @Bean 注解:在配置类中,可以使用@Bean注解来定义Bean,将某个方法的返回值作为一个bean
使用 @Import注解:可以使用@Import注解来导入其他配置类或者直接导入Bean类
使用ImportSelector或者ImportBeanDefinitionRegistrar接口:配合@Import注解,可以实现更复杂的逻辑来定义Bean
使用工厂方法:可以定义一个工厂类,然后在工厂类中定义静态或者实例方法来创建Bean
# 2. Bean的作用域
作用域
在Spring框架中,Bean的作用域(Scope)决定了Bean在应用程序各种上下文中的生命周期和可见性,可通过@Scope注解指定作用域
Singleton:这是默认的作用域。对于每个Spring IoC容器,每个单例Bean的定义都对应一个对象实例
Prototype:对于每个Bean定义,每次请求都会创建一个新的对象实例
Request:对于每个Bean定义,每个HTTP请求都会创建一个新的对象实例。这个作用域只在web-aware的Spring ApplicationContext中有效
Session:对于每个Bean定义,每个HTTP会话都会创建一个新的对象实例。这个作用域只在web-aware的Spring ApplicationContext中有效
Application:对于每个Bean定义,每个ServletContext都会创建一个新的对象实例。这个作用域只在web-aware的Spring ApplicationContext中有效
Websocket:对于每个Bean定义,每个WebSocket都会创建一个新的对象实例。这个作用域只在web-aware的Spring ApplicationContext中有效
# 3. BeanDefinitionReader
笔记
BeanDefinitionReader的作用是读取Spring配置文件中的内容,将其转换为IoC容器内部的数据结构:BeanDefinition
public void getBeanDefinition(){
ClassPathResource resource = new ClassPathResource("application_context.xml");
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory);
reader.loadBeanDefinitions(resource);
}
2
3
4
5
6
上述的XmlBeanDefinitionReader类作为 AbstractBeanDefinitionReader 的扩展类,继承了 AbstractBeanDefinitionReader 所有的方法,同时也扩展了很多新的方法,主要用于读取 XML 文件中定义的 bean
代码分析:
- 获取xml文件资源
- 获取BeanFactory,DefaultListableBeanFactory()是最重要的实现类之一
- 根据新建的 BeanFactory 创建一个BeanDefinitionReader对象,该Reader 对象为资源的解析器
- 装载资源: 整个过程就分为三个步骤:资源定位、装载、注册
4.1 定位: IoC 容器的第一步就是需要定位这个外部资源
4.2 装载: 装载就是 BeanDefinition 的载入,BeanDefinitionReader 读取、解析 Resource 资源,也就是将用户定义的 Bean 表示成 IoC 容器 的内部数据结构:BeanDefinition。在 IoC 容器内部维护着一个 BeanDefinition Map 的数据结构,在配置文件中每一个<bean>都对应着一个 BeanDefinition 对象。
4.3 注册:向 IoC 容器注册在第二步解析好的 BeanDefinition,这个过程是通过 BeanDefinitionRegistry 接口来实现的。本质上是将解析得到的 BeanDefinition 注入到一个 HashMap 容器中,IoC 容器就是通过这个 HashMap HashMap 来维护这些 BeanDefinition 的
注意:此过程并没有完成依赖注入,依赖注册是发生在应用第一次调用 getBean()向容器索要 Bean 时
# 4. BeanFactoryPostProcessor
笔记
BeanFactoryPostProcessor允许我们在Spring容器实例化bean之前,对bean的定义(配置元数据)进行修改。例如,我们可以修改bean的scope,是否懒加载,是否是抽象的,以及bean的属性值等。
public class CustomBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
// 获取bean定义
BeanDefinition beanDefinition = beanFactory.getBeanDefinition("beanName");
// 修改bean定义
beanDefinition.setScope(BeanDefinition.SCOPE_PROTOTYPE);
}
}
2
3
4
5
6
7
8
9
10
代码分析:通过实现BeanFactoryPostProcessor的postProcessBeanFactory()方法实现修改BeanDefinition
BeanFactoryPostProcessor的一些其他实现子类扩展了一些功能,例如PropertySourcesPlaceholderConfigurer是一个BeanFactoryPostProcessor,它可以解析@PropertySource注解,用于加载属性文件,ConfigurationClassPostProcessor 可以解析 @ComponentScan,@Bean,@Import,@ImportResource等等
# 5. BeanFactory
笔记
BeanFactory是Spring框架的核心接口,它负责实例化、定位、配置应用程序中的对象以及建立这些对象间的依赖。简单来说,BeanFactory就是一个管理Bean的工厂,它主要负责初始化各种Bean,并调用它们的生命周期方法
以下是BeanFactory的主要功能:
实例化Bean:BeanFactory通过反射根据配置信息创建Bean的实例
管理Bean的生命周期:BeanFactory负责调用Bean的初始化方法和销毁方法,管理Bean的生命周期
处理Bean的依赖关系:BeanFactory负责处理Bean之间的依赖关系,例如自动装配和依赖注入
提供Bean的查询和查找功能:BeanFactory提供了一些方法,例如getBean(),containsBean(),isSingleton(),isPrototype(),isTypeMatch(),getType()和getAliases(),用于查询和查找Bean
# 6. populateBean
populateBean方法是Spring框架中AbstractAutowireCapableBeanFactory类的一个重要方法。它主要负责Bean实例的各种依赖注入,包括自动注入(名称注入和类型注入)、注解注入(@Autowired 和 @Value 等)、手动注入等。
以下是populateBean方法的主要步骤:
激活InstantiationAwareBeanPostProcessor后置处理器的postProcessAfterInstantiation方法:在实例化bean之后,Spring属性填充之前执行的钩子方法
解析依赖注入的方式,将属性装配到PropertyValues中:根据注入方式(如名称注入或类型注入)解析属性,并将解析的属性值添加到PropertyValues中
激活InstantiationAwareBeanPostProcessor#postProcessProperties:对@AutoWired标记的属性进行依赖注入
将解析的值用BeanWrapper进行包装:将PropertyValues中的属性值应用到Bean实例中
# 7. Aware
笔记
在Spring框架中,Aware接口是一组标记接口,用于在Bean装配的过程中获取Spring容器中提供的一些核心组件或运行时上下文等信息。实现了Aware接口的Bean可以访问Spring容器
以下是一些常见的Aware接口:
BeanNameAware:可以获取到Spring容器中Bean的名称
BeanFactoryAware:可以获取到当前的BeanFactory,从而可以调用容器的服务
ApplicationContextAware:可以获取到当前的ApplicationContext,从而可以调用容器的服务
MessageSourceAware:可以获取到Message Source,从而可以获取相关的文本信息
ApplicationEventPublisherAware:可以获取到ApplicationEventPublisher,从而可以发布事件
ResourceLoaderAware:可以获取到ResourceLoader,从而可以加载外部资源文件
# 8. BeanPostProcessor
笔记
BeanPostProcessor是Spring框架中的一个重要接口,它允许我们在Spring容器实例化、配置和初始化Bean之后,以及在销毁Bean之前,对Bean进行一些自定义的操作
以下是BeanPostProcessor的主要功能:
在初始化之前和之后修改Bean:BeanPostProcessor接口定义了两个方法:postProcessBeforeInitialization和postProcessAfterInitialization。这两个方法分别在Bean初始化之前和之后被调用,允许我们在这两个时间点对Bean进行修改
处理自定义注解:BeanPostProcessor可以用来处理自定义注解。例如,我们可以创建一个BeanPostProcessor,在postProcessBeforeInitialization方法中检查Bean是否有某个自定义注解,如果有,则进行相应的处理
包装Bean:BeanPostProcessor还可以用来包装Bean。例如,我们可以在postProcessAfterInitialization方法中返回一个包装了原始Bean的代理对象(cglib或者jdk代理)
# 9. init-method
笔记
在Spring框架中,init-method属性用于在bean初始化时指定执行的方法。这个方法会在bean实例化并设置好属性之后被调用,通常用于完成一些初始化工作
以下是一些常见的例子:
- 加载数据:初始化方法可以用于在启动应用程序后立即加载一些数据。例如,你可能需要从数据库中拉取一些数据并缓存起来
- 读取配置变量:初始化方法可以用于读取配置文件中的变量,并将这些变量设置到Bean的属性中
- 设置资源:初始化方法可以用于设置一些资源,例如打开文件或者网络连接
- 执行业务逻辑:初始化方法可以用于执行一些业务逻辑,例如计算一些值或者更新一些状态
需要注意的是,init-method指定的初始化方法会在Bean实例化并设置好属性之后被调用,因此你可以在这个方法中访问和修改Bean的所有属性
# 10. 三级缓存
笔记
Spring中的循环依赖是指在Spring应用程序中,两个或多个类之间存在彼此依赖的情况,形成一个循环依赖链。例如,A依赖B,B又依赖A,A和B之间就形成了相互依赖的关系
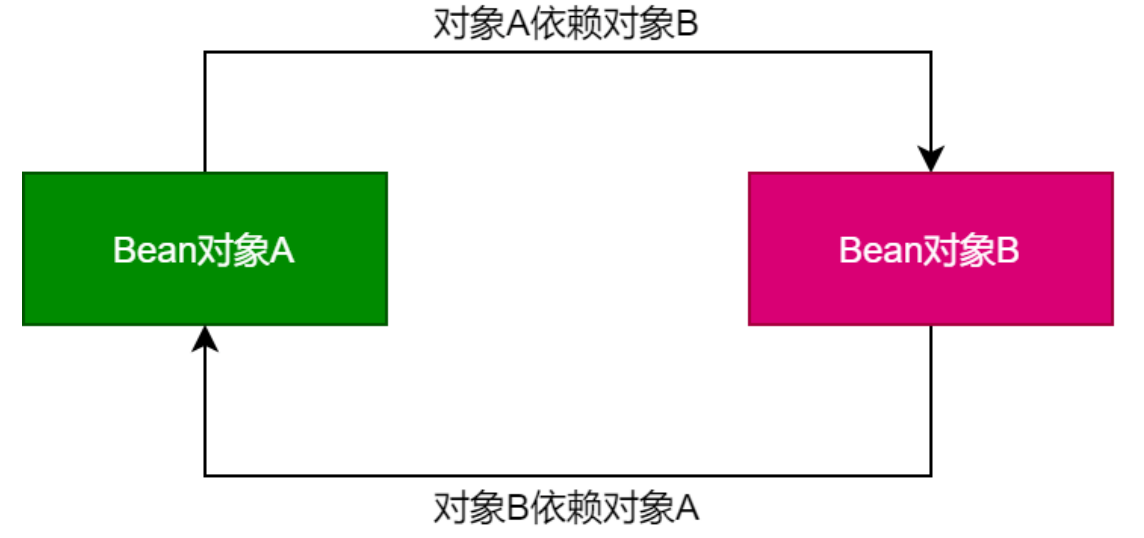
Spring解决循环依赖的方式主要是通过三级缓存 这三级缓存的作用是在创建Bean的过程中,当一个Bean在初始化时需要另一个Bean的实例,而另一个Bean又需要第一个Bean的实例时,Spring会先将已经实例化但还未完成初始化的Bean提前暴露出去,也就是加入到缓存中,这样就可以被其他Bean引用,从而打破循环依赖
// 一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
// 三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
2
3
4
5
6
- 一级缓存用于存放容器中可以使用的bean或者代理bean (成熟品)
- 二级缓存用于存放实例化的原始对象(的代理对象)(半成品),以让在有多重循环依赖的时候其它对象都从二级缓存中拿到同一个当前原始对象(的代理对象),并且只有在调用了三级缓存中的ObjectFactory的getObject() 方法获取原始对象(的代理对象)时,才会将原始对象(的代理对象)放入二级缓存
调用三级缓存中的ObjectFactory的getObject() 方法获取原始对象(的代理对象)这种情况只会发生在有循环依赖的时候,所以,二级缓存在没有循环依赖的情况下不会被使用到。
- 三级缓存用于存放原始对象对应的ObjectFactory,每生成一个原始对象,都会将这个原始对象对应的ObjectFactory放到三级缓存中,通过调用ObjectFactory的getObject() 方法,就能够在需要动态代理的情况下为原始对象生成代理对象并返回,否则返回原始对象,以此来处理循环依赖时还需要动态代理的情况。
ObjectFactory是一个函数式接口,仅有一个方法,可以传入lambda表达式或者内部类,通过调用getObject()方法执行具体的逻辑,例如getEarlyBeanReference(),实现在需要动态代理的情况下为原始对象生成代理对象并返回,否则返回原始对象
// 将Aservice添加三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
// 添加B的A属性时从三级中找A的ObjectFactory类型一个匿名内部类对象,从而触发匿名内部类getEarlyBeanReference()方法回调,进入创建AService切面代理对象逻辑
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
// 原始对象
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
//判断后置处理器是否实现了SmartInstantiationAwareBeanPostProcessor接口
//调用SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
🔎然而,Spring解决循环依赖是有前置条件的:
- 出现循环依赖的Bean必须要是单例。
- 依赖注入的方式不能全是构造器注入的方式
具体循环依赖解决流程实现图: 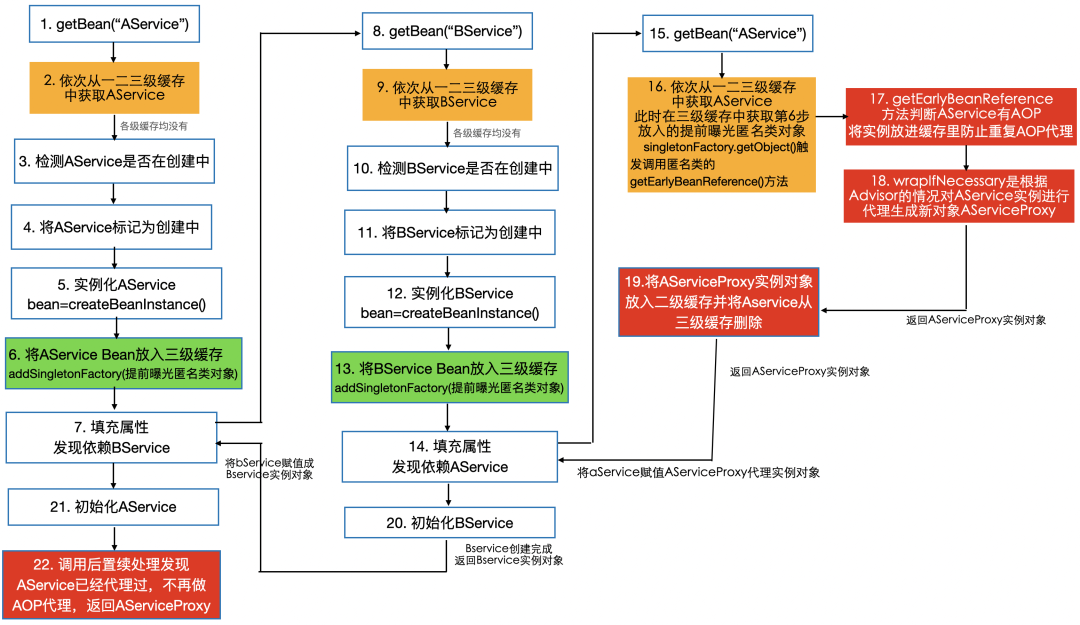
只使用一级缓存的问题
一级缓存中预期存放的是一个正常完整的bean,而如果只用一级缓存来解决循环依赖,那么一级缓存中会在某个时间段存在不完整的bean,这是不安全的。
什么不直接使用一级缓存和二级缓存解决循环依赖
使用一级缓存和二级缓存确实可以解决循环依赖,但是这要求每个原始对象创建出来后就立即生成动态代理对象(如果有的话),然后将这个动态代理对象放入二级缓存,这就打破了Spring对AOP的设计原则,即:在对象初始化完毕后,再去创建代理对象。
🔎所以引入三级缓存,并且在三级缓存中存放一个对象的ObjectFactory,目的就是:延迟代理对象的创建
这里延迟到啥时候创建呢,有两种情况:
- 第一种就是确实存在循环依赖,那么没办法,只能在需要的时候就创建出来代理对象然后放到二级缓存中
- 第二种就是不存在循环依赖,那就是正常的在初始化的后置处理器中创建。
因此不直接使用一级缓存和二级缓存来解决循环依赖的原因就是:希望在不存在循环依赖的情况下不破坏Spring对AOP的设计原则。