知识点总结二
知识点总结二
# 1. 优惠券秒杀
# 1.1 全局唯一ID
当用户抢购优惠券后,就会生成订单并保存到订单表中,而订单表如果使用数据库自增ID就存在一些问题:id的规律性太明显以及受单表数据量的限制
全局ID生成器 :是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特性:
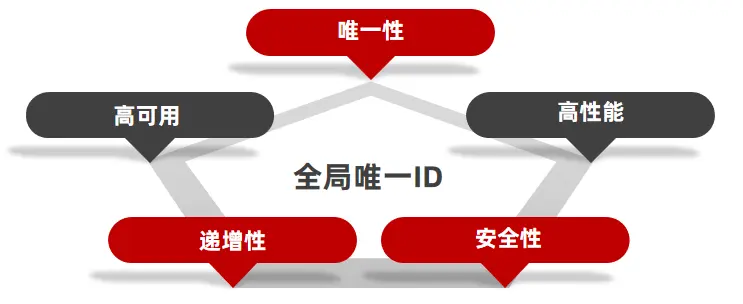
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:
 ID的组成部分:
ID的组成部分:
- 符号位:1bit,永远为0
- 时间戳:31bit,以秒为单位,可以使用69年
- 序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
# 1.2 优惠券超卖问题——乐观锁解决方案
超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁:而对于加锁,我们通常有两种解决方案:
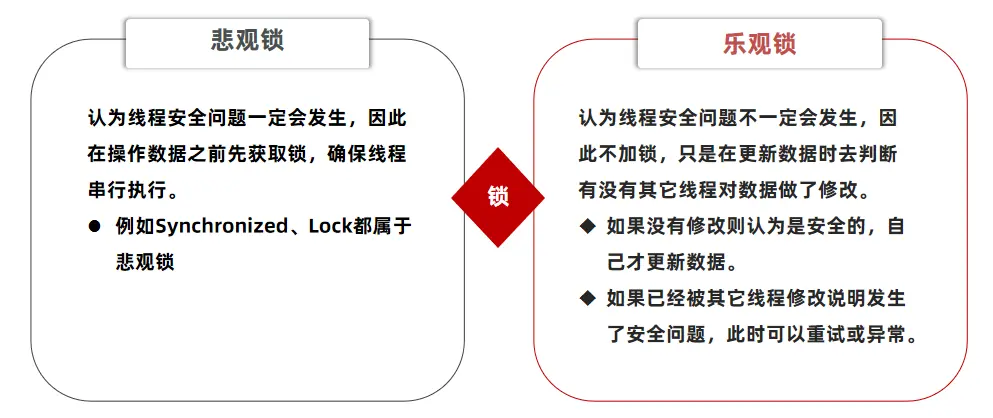
乐观锁适用于更新数据的场景
# 1.2.1 版本号法
乐观锁会有一个版本号,每次操作数据会对版本号+1,再提交回数据时,会去校验是否比之前的版本大1 ,如果大1 ,则进行操作成功,这套机制的核心逻辑在于,如果在操作过程中,版本号只比原来大1 ,那么就意味着操作过程中没有人对他进行过修改,他的操作就是安全的,如果不大1,则数据被修改过
# 1.2.2 cas法(Compare and Swap):
CAS 操作包括三个参数:内存地址 V、旧的预期值 A 和新的值 B。
CAS 操作的执行过程如下:
① 读取内存地址 V 中的当前值。
② 判断读取的值是否等于旧的预期值 A。如果相等,则执行第 3 步;否则,表示其他线程已经修改了该值,操作失败。
③ 将内存地址 V 的值更新为新的值 B。
CAS 操作是原子的且无阻塞的(自旋)。当多个线程同时进行 CAS 操作时,只有一个线程的 CAS 操作能成功,其余线程的 CAS 操作会失败。因此,通过循环不断地重试 CAS 操作,可以在无锁的情况下实现对共享数据的并发操作。
# 1.2.3 自旋
自旋
自旋是在并发编程中一种线程等待的技术,它通常用于竞争条件的处理或者临界区的访问控制。 当一个线程发现自己无法立即进入某个临界区,但预计在稍后会成功进入时,它可以选择进行自旋操作。自旋操作是指线程忙等待,在循环中反复检查是否满足进入临界区的条件,而不是进入休眠状态或者阻塞等待其他线程释放资源。
自旋的目的是为了避免线程切换的开销。线程在自旋期间会持续占用 CPU 时间,不会让出 CPU,因此在自旋期间其他线程无法执行。如果临界区的延迟时间很短,或者竞争情况不频繁,自旋可能是一种有效的等待策略,可以减少线程上下文切换的开销。
然而,自旋也有一些限制和不足之处。如果自旋时间过长,会导致浪费大量的 CPU 资源,降低系统的整体性能。此外,在多核处理器上,自旋可能会导致争用共享资源,影响其他线程的执行。因此,在使用自旋时需要根据具体情况权衡利弊,并合理选择自旋次数或转而使用其他等待机制,如阻塞等待或信号量等。
# 1.3 一人一单秒杀问题——集群环境
# 1.3.1 synchronized锁
synchronized配置的锁无法解决在集群环境中的线程安全问题
有关锁失效原因分析 由于现在我们部署了多个tomcat,每个tomcat都有一个属于自己的jvm,那么假设在服务器A的tomcat内部,有两个线程,这两个线程由于使用的是同一份代码,那么他们的锁对象是同一个,是可以实现互斥的,但是如果现在是服务器B的tomcat内部,又有两个线程,但是他们的锁对象写的虽然和服务器A一样,但是锁对象却不是同一个,所以线程3和线程4可以实现互斥,但是却无法和线程1和线程2实现互斥,这就是 集群环境下,syn锁失效的原因,在这种情况下,我们就需要使用分布式锁来解决这个问题。
# 1.3.2 分布式锁
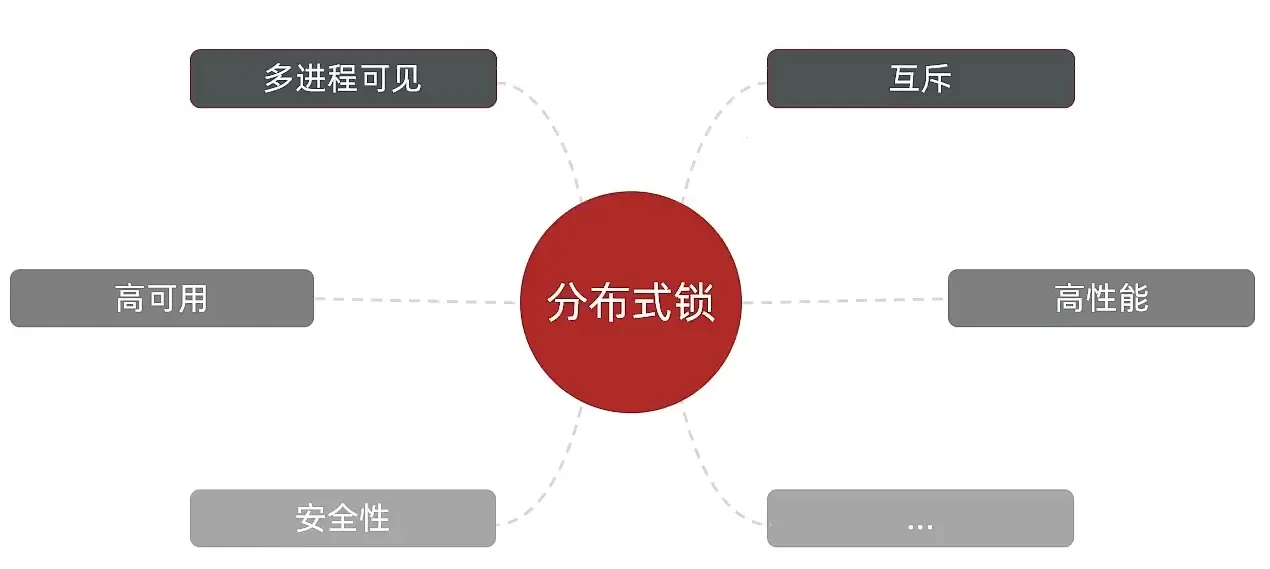
多进程可见指的是多个进程之间都能感知到变化的意思
常见分布式锁解决方案: 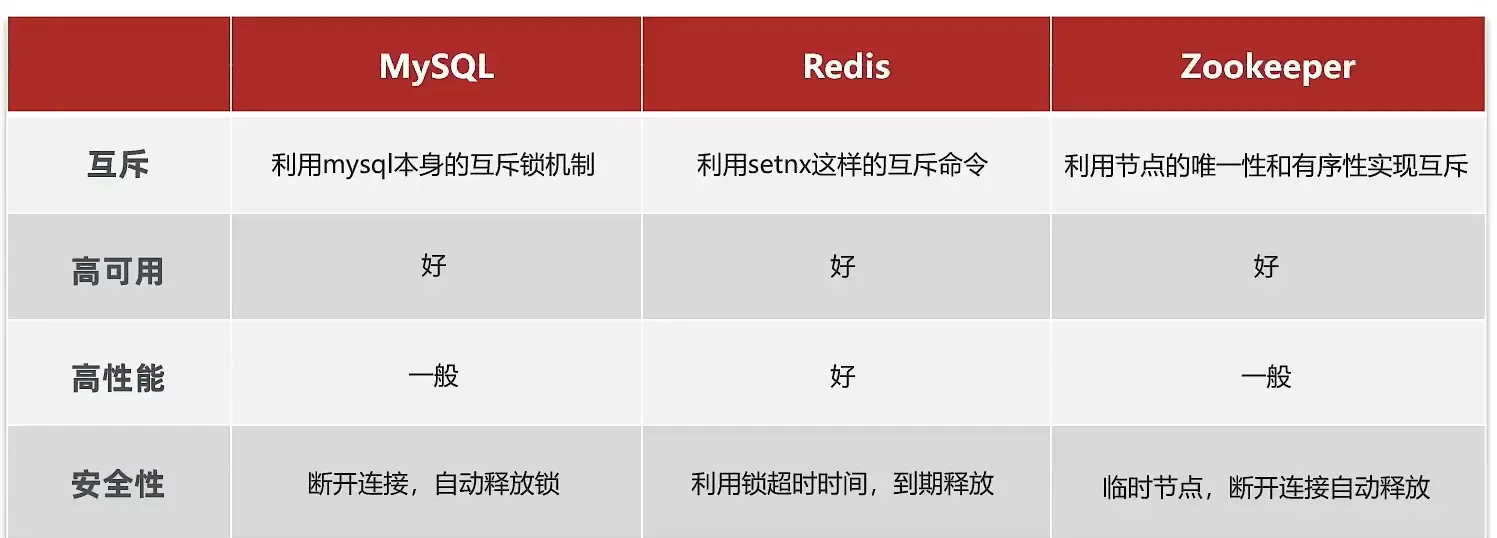
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性
# 1.3.3 分布式锁-redission
Redission
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。

之前使用Redis的setnx实现锁,但存在以下问题:
重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都是使用synchronized修饰的,假如他在一个方法内,调用另一个方法,那么此时如果是不可重入的,不就死锁了吗?
不可重试:是指目前的分布式只能尝试一次,我们认为合理的情况是:当线程在获得锁失败后,他应该能再次尝试获得锁。
超时释放:我们在加锁时增加了过期时间,这样的我们可以防止死锁,但是如果卡顿的时间超长,虽然我们采用了lua表达式防止删锁的时候,误删别人的锁,但是毕竟没有锁住,有安全隐患
主从一致性: 如果Redis提供了主从集群,当我们向集群写数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。
# 1.3.4 分布式锁-redission可重入锁原理
在分布式锁中,采用hash结构用来存储锁,其中大key表示表示这把锁是否存在,用小key表示当前这把锁被哪个线程持有,所以接下来我们一起分析一下当前的这个lua表达式
-- 判断锁不存在,则抢锁成功
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
-- 判断锁属于自己——threadId
-- hincrby:将当前这个锁的value进行+1(实现可重入)
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
-- 如果以上两个条件都不满足,则表示当前这把锁抢锁失败,返回过期时间
"return redis.call('pttl', KEYS[1]);"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
KEYS[1] : 锁名称
ARGV[1]: 锁失效时间
ARGV[2]: id + ":" + threadId; 锁的小key
# 2. 异步秒杀——消息队列
优化方案:我们将耗时比较短的逻辑判断放入到redis中,比如是否库存足够,比如是否一人一单,这样的操作,只要这种逻辑可以完成,就意味着我们是一定可以下单完成的,我们只需要进行快速的逻辑判断,根本就不用等下单逻辑走完,我们直接给用户返回成功, 再在后台开一个线程,后台线程慢慢的去执行queue里边的消息
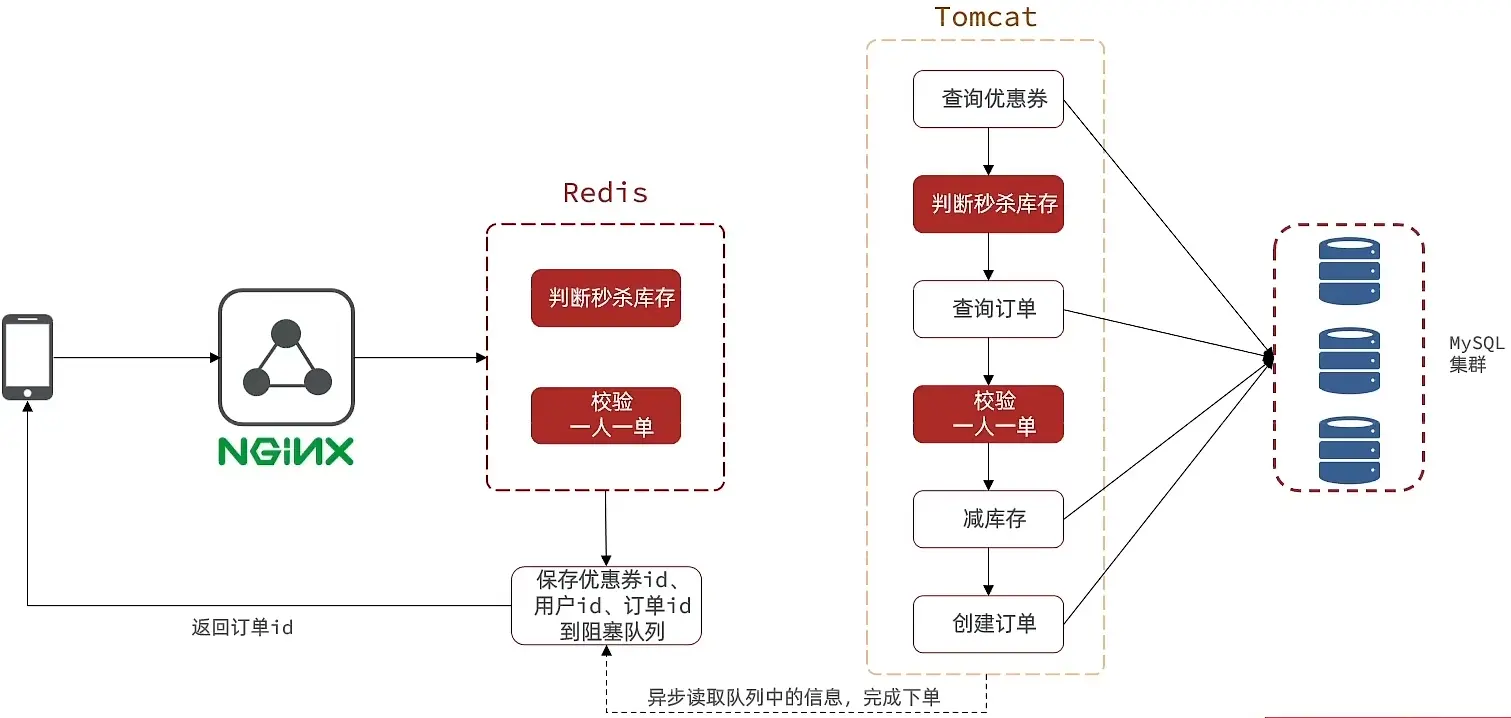
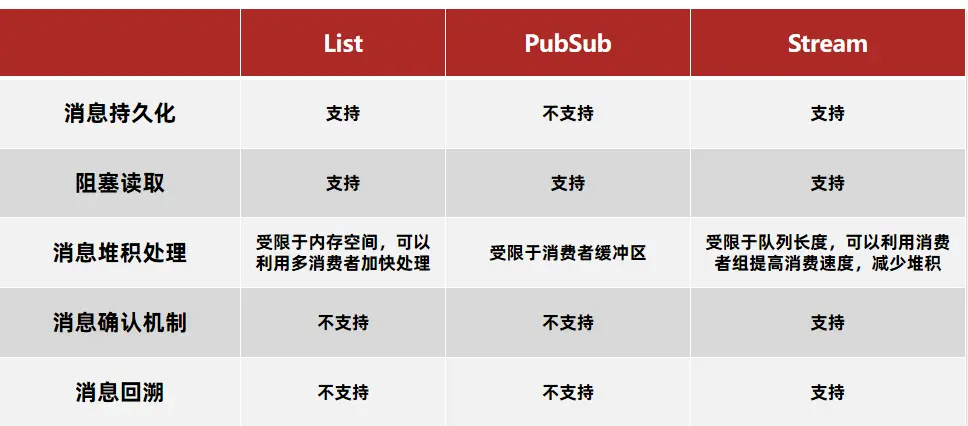
# 2.1 基于List实现消息队列
Redis的list数据结构是一个双向链表,很容易模拟出队列效果;队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。
基于List的消息队列有哪些优缺点? 优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
- 无法避免消息丢失
- 只支持单消费者
# 2.2 基于PubSub的消息队列
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
基于PubSub的消息队列有哪些优缺点? 优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
# 2.3 基于Stream的消息队列
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
STREAM类型消息队列的XREAD命令特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
# 2.4 基于Stream的消息队列-消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。
具备下列特点: 
消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次