知识点总结一
知识点总结一
简介
该项目基于Redis进行开发,采用前后端分离的开发模式,使用nginx作为前端服务器
# 1. Tomcat的运行原理
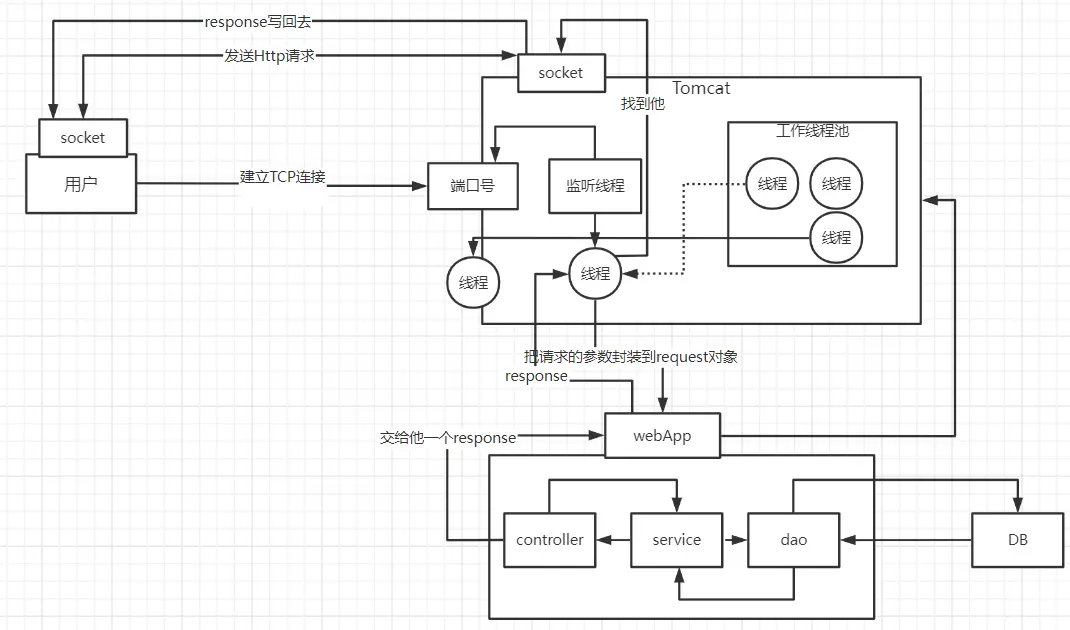
① 当用户发起请求时,会访问我们向tomcat注册的端口,任何程序想要运行,都需要有一个线程对当前端口号进行监听
② 当监听线程知道用户想要和tomcat连接时,那会由监听线程创建socket连接,socket都是成对出现的,用户通过socket互相传递数据
③ 当tomcat端的socket接收到数据后,此时监听线程会从tomcat的线程池中取出一个线程执行用户请求
④ 在我们的服务部署到tomcat后,线程会找到用户想要访问的工程,然后用这个线程转发到工程中的controller,service,dao中,并且访问对应的DB,在用户执行完请求后,再统一返回,再找到tomcat端的socket,再将数据写回到用户端的socket,完成请求和响应
每个用户其实对应都是去找tomcat线程池中的一个线程来完成工作的,使用完成后再进行回收,既然每个请求都是独立的,所以在每个用户去访问我们的工程时,我们可以使用threadlocal来做到线程隔离,每个线程操作自己的一份数据
温馨小贴士:关于threadlocal
如果小伙伴们看过threadLocal的源码,你会发现在threadLocal中,无论是他的put方法和他的get方法, 都是先从获得当前用户的线程,然后从线程中取出线程的成员变量map,只要线程不一样,map就不一样,所以可以通过这种方式来做到线程隔离
# 2. 短信登录
当基于session实现短信登录时,会出现session共享问题,所以采用Redis解决方案
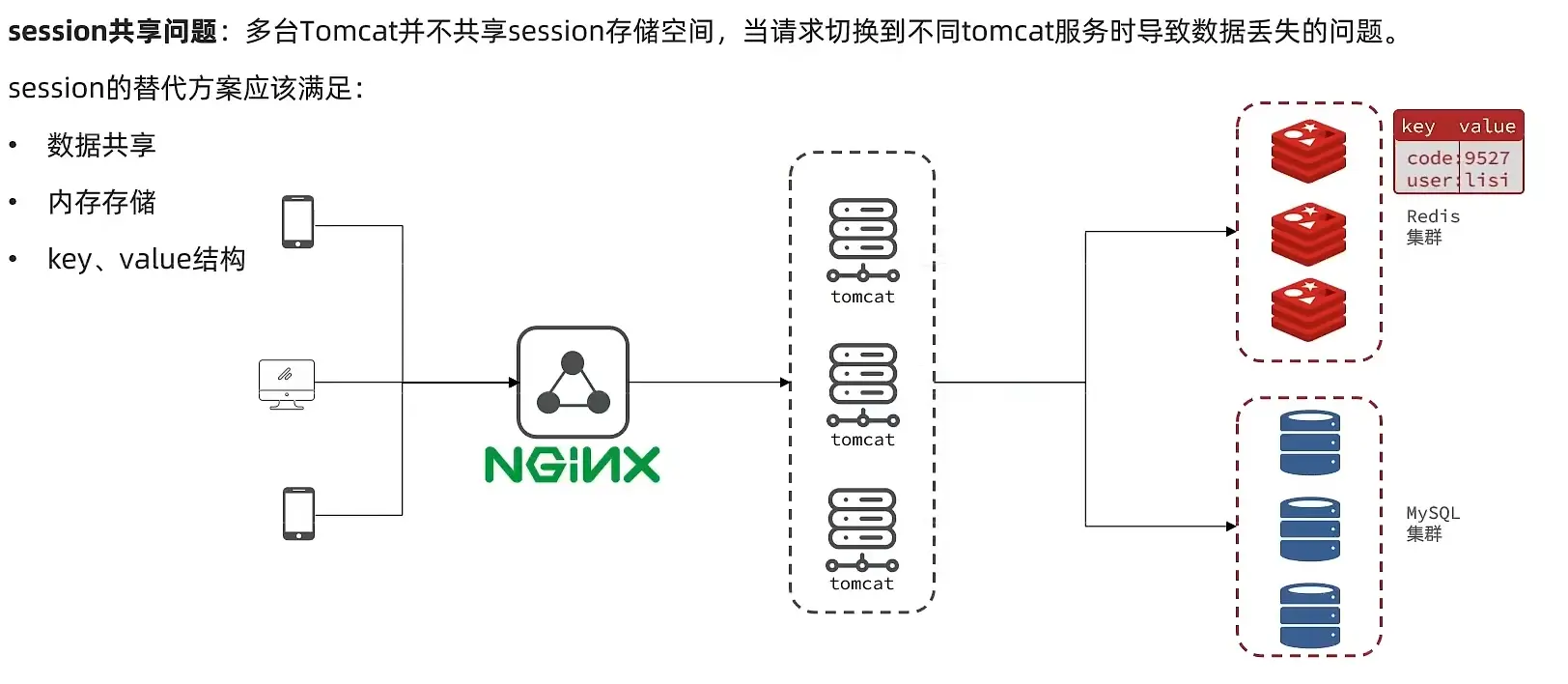
# 2.1 基于Redis实现
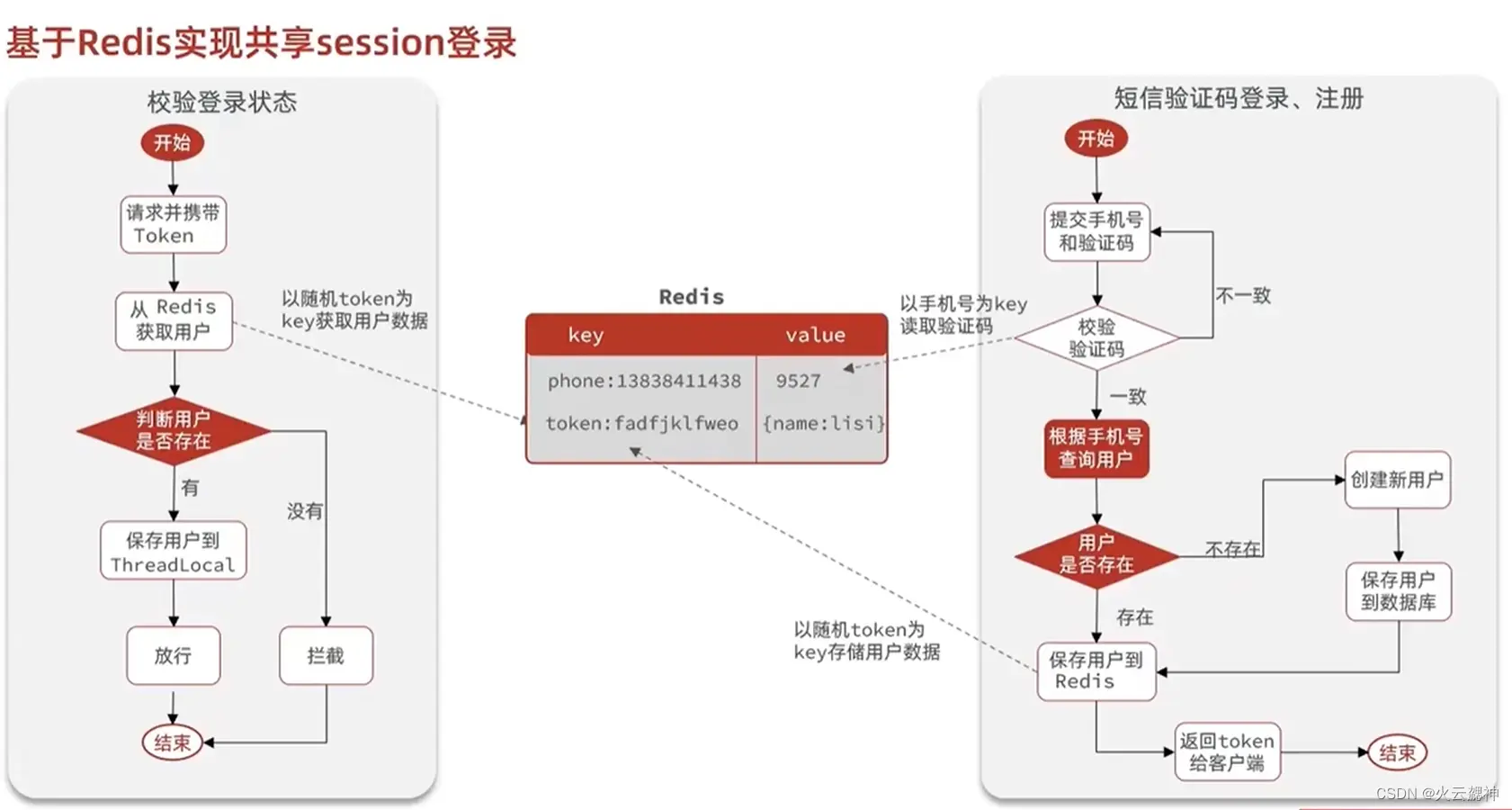
- 将随机生成的token作为key值,保证了唯一性的同时又方便携带,同时token有对应的存活时间
- 使用
Redis的 Hash 数据结构存储用户数据(对象)
# 2.2 登录拦截器
方案一: 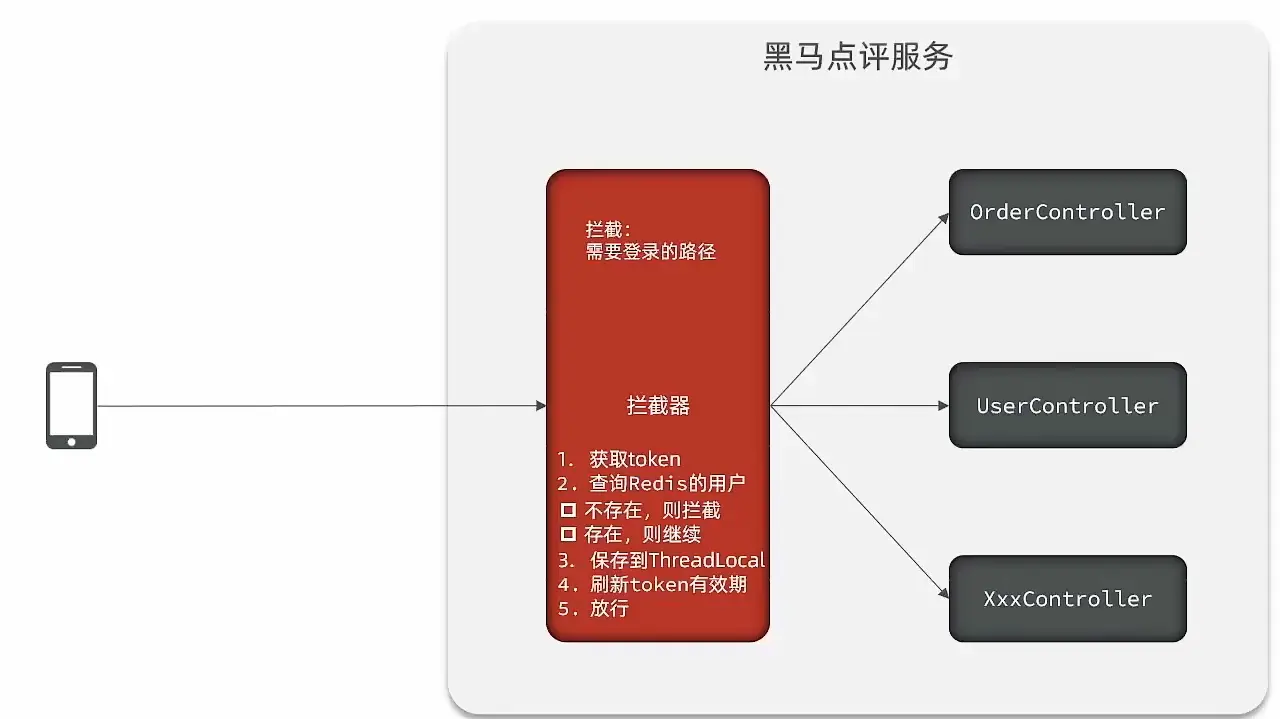 在这个方案中,确实可以实现对应路径的拦截,同时刷新登录token令牌的存活时间,但是现在这个拦截器他只是拦截需要被拦截的路径,假设当前用户访问了一些不需要拦截的路径,那么这个拦截器就不会生效,所以此时令牌刷新的动作实际上就不会执行,所以这个方案他是存在问题的
在这个方案中,确实可以实现对应路径的拦截,同时刷新登录token令牌的存活时间,但是现在这个拦截器他只是拦截需要被拦截的路径,假设当前用户访问了一些不需要拦截的路径,那么这个拦截器就不会生效,所以此时令牌刷新的动作实际上就不会执行,所以这个方案他是存在问题的
方案二: 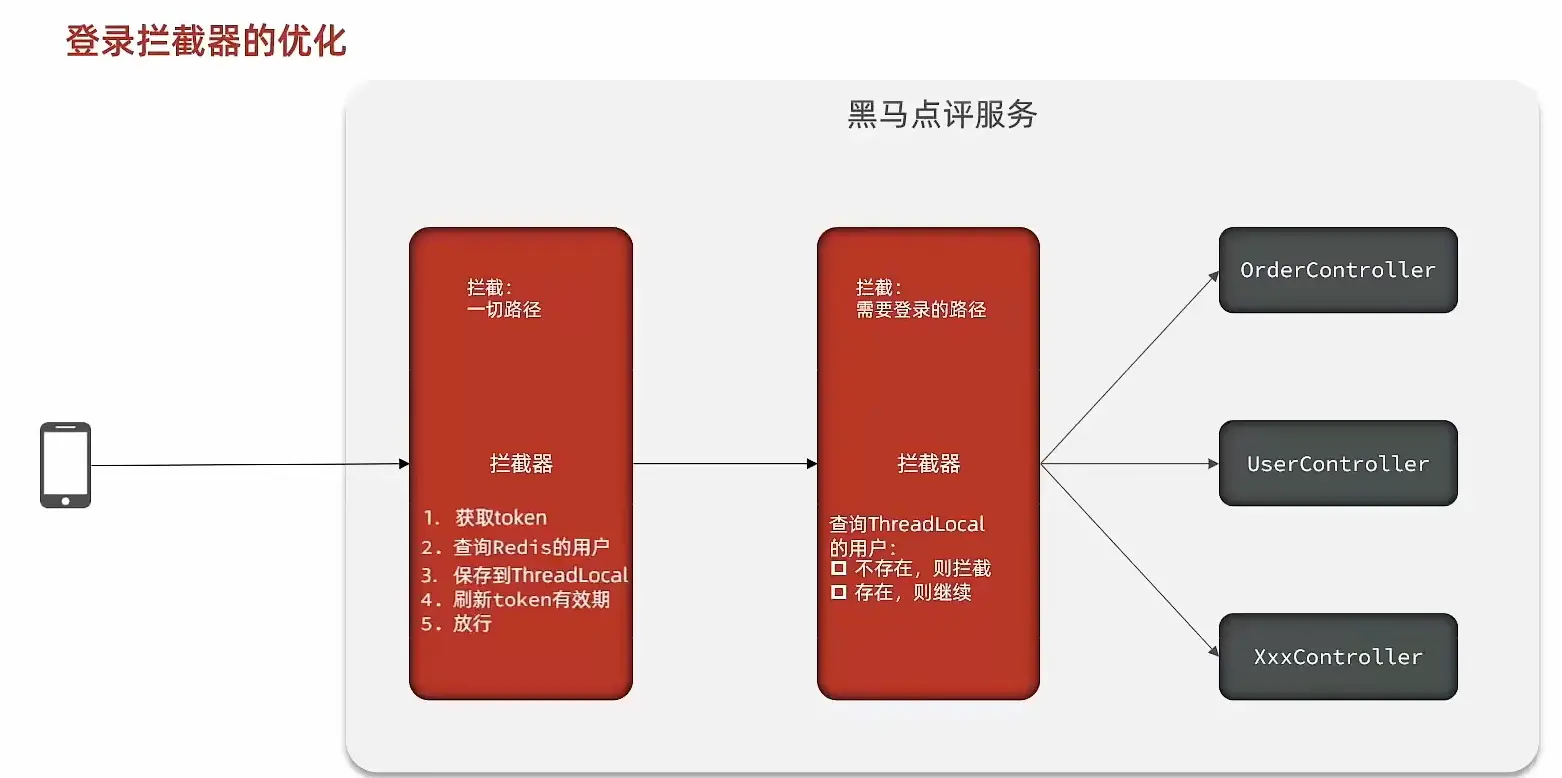 既然之前的拦截器无法对不需要拦截的路径生效,那么我们可以添加一个拦截器,在第一个拦截器中拦截所有的路径,把第二个拦截器做的事情放入到第一个拦截器中,同时刷新令牌,因为第一个拦截器有了threadLocal的数据,所以此时第二个拦截器只需要判断拦截器中的user对象是否存在即可,完成整体刷新功能。
既然之前的拦截器无法对不需要拦截的路径生效,那么我们可以添加一个拦截器,在第一个拦截器中拦截所有的路径,把第二个拦截器做的事情放入到第一个拦截器中,同时刷新令牌,因为第一个拦截器有了threadLocal的数据,所以此时第二个拦截器只需要判断拦截器中的user对象是否存在即可,完成整体刷新功能。
# 3. 商户查询缓存
# 3.1 实现思路
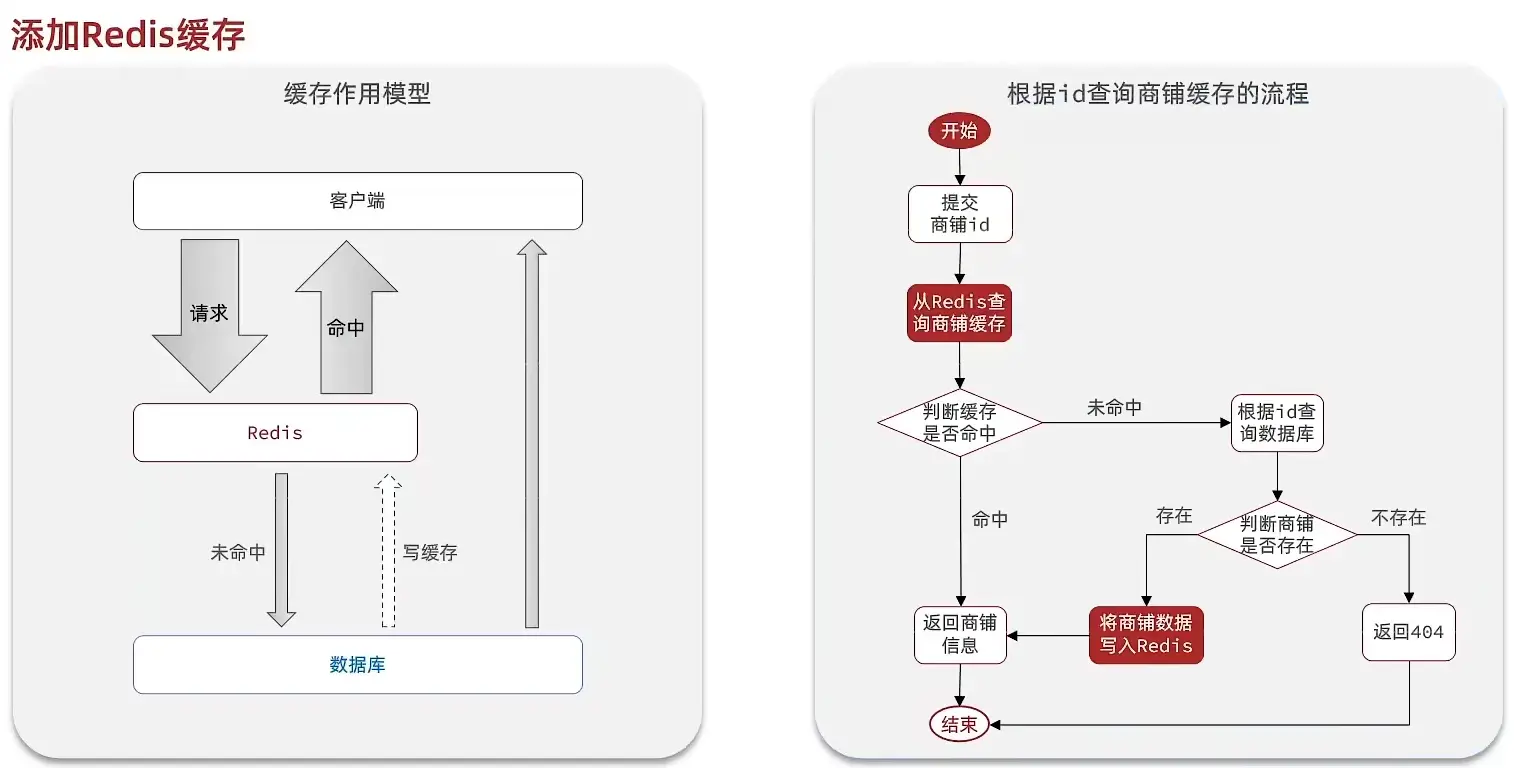
# 3.2 缓存更新策略
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,所以redis会对部分数据进行更新
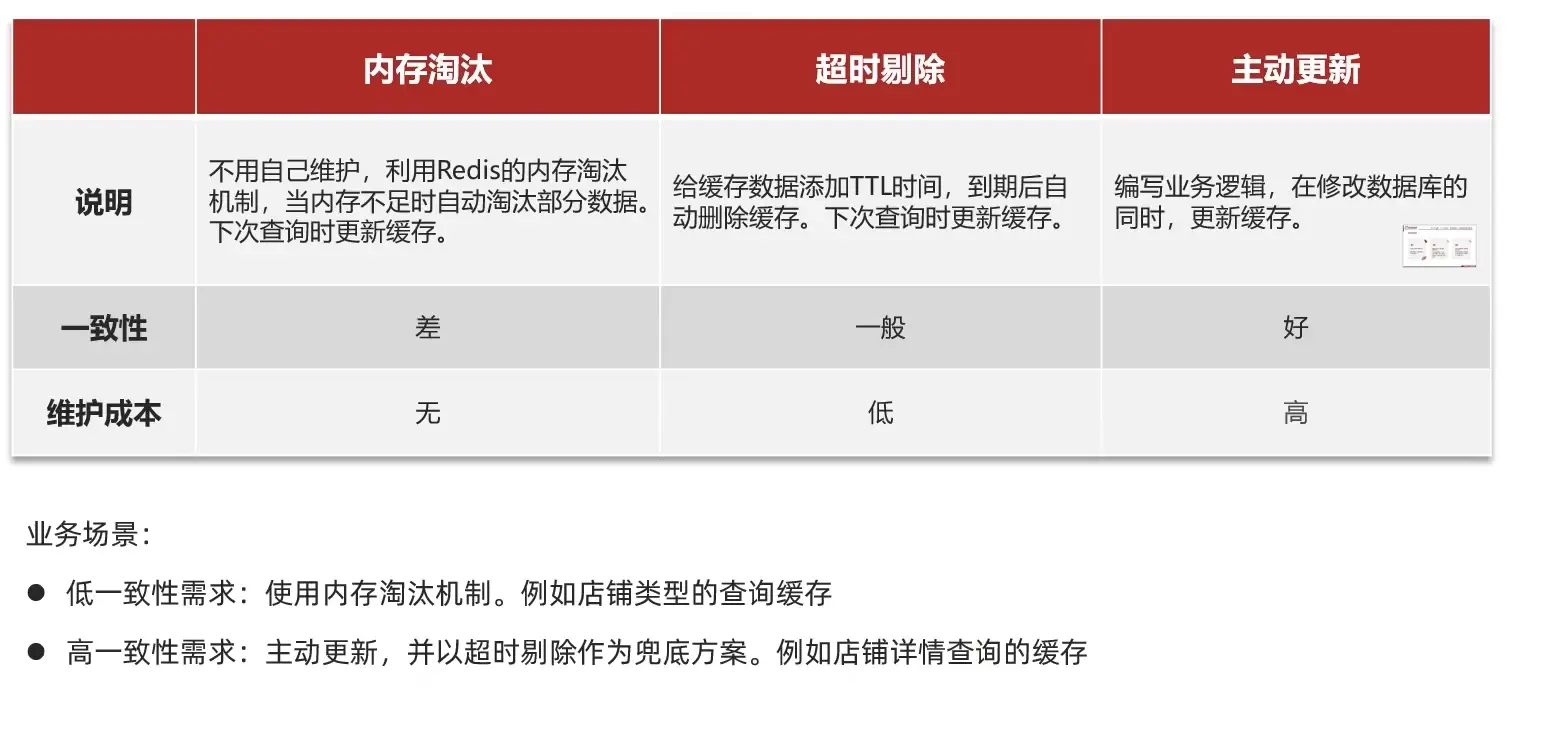
# 3.2.1 数据库缓存不一致解决方案:
由于我们的缓存的数据源来自于数据库,而数据库的数据是会发生变化的,因此,如果当数据库中数据发生变化,而缓存却没有同步,此时就会有一致性问题存在,其后果是:
用户使用缓存中的过时数据,就会产生类似多线程数据安全问题,从而影响业务,产品口碑等;怎么解决呢?有如下几种方案

# 3.2.2 数据库和缓存不一致采用什么方案
综合考虑使用方案一,但是方案一调用者如何处理呢?这里有几个问题
操作缓存和数据库时有三个问题需要考虑:
- 删除缓存还是更新缓存?
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存
如果采用第一个方案,那么假设我们每次操作数据库后,都操作缓存,但是中间如果没有人查询,那么这个更新动作实际上只有最后一次生效,中间的更新动作意义并不大,我们可以把缓存删除,等待再次查询时,将缓存中的数据加载出来
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
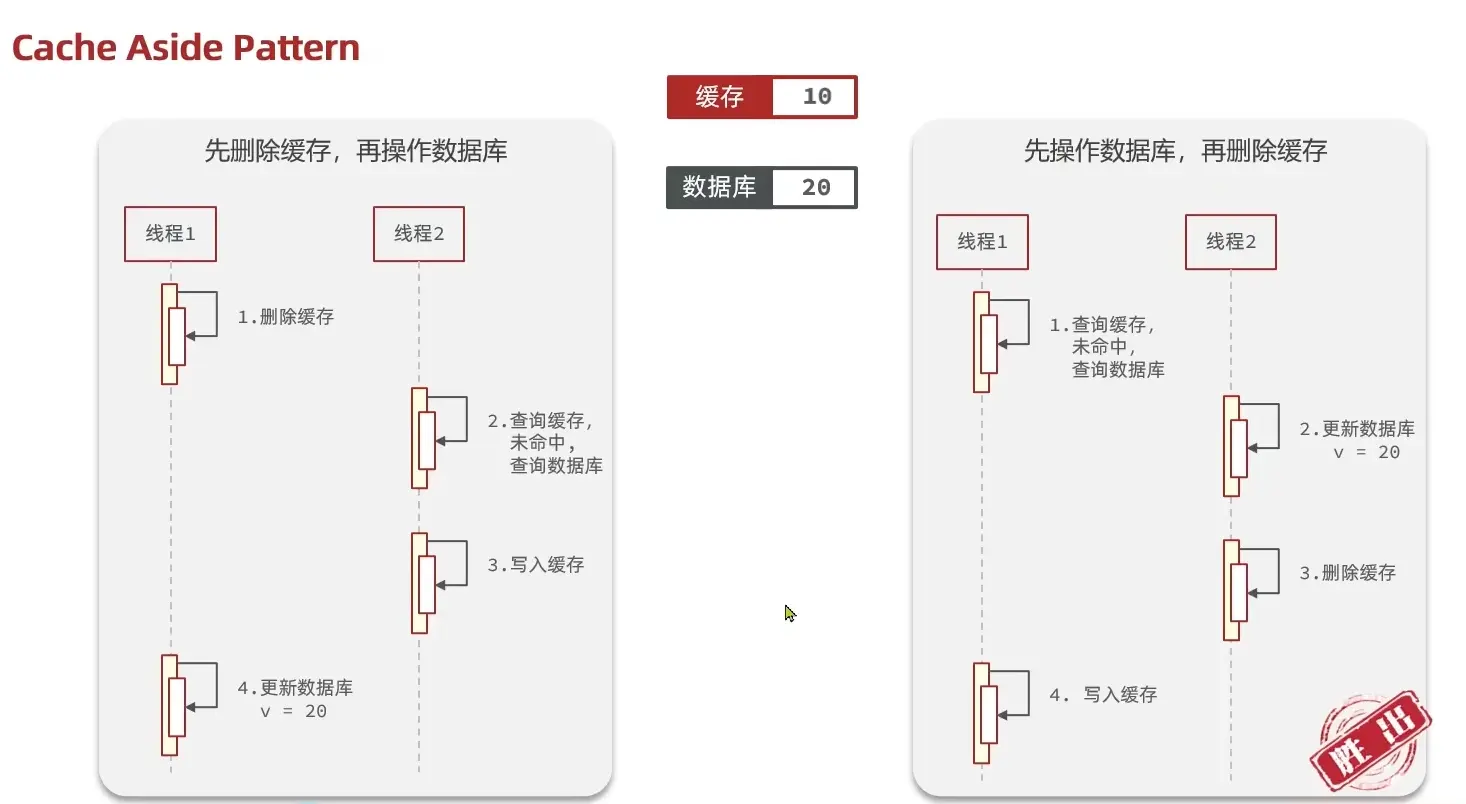
先操作缓存还是先操作数据库?
- 先删除缓存,再操作数据库
- 先操作数据库,再删除缓存
应该具体操作缓存还是操作数据库,我们应当是先操作数据库,再删除缓存,原因在于,如果你选择第一种方案,在两个线程并发来访问时,假设线程1先来,他先把缓存删了,此时线程2过来,他查询缓存数据并不存在,此时他写入缓存,当他写入缓存后,线程1再执行更新动作时,实际上写入的就是旧的数据,新的数据被旧数据覆盖了。
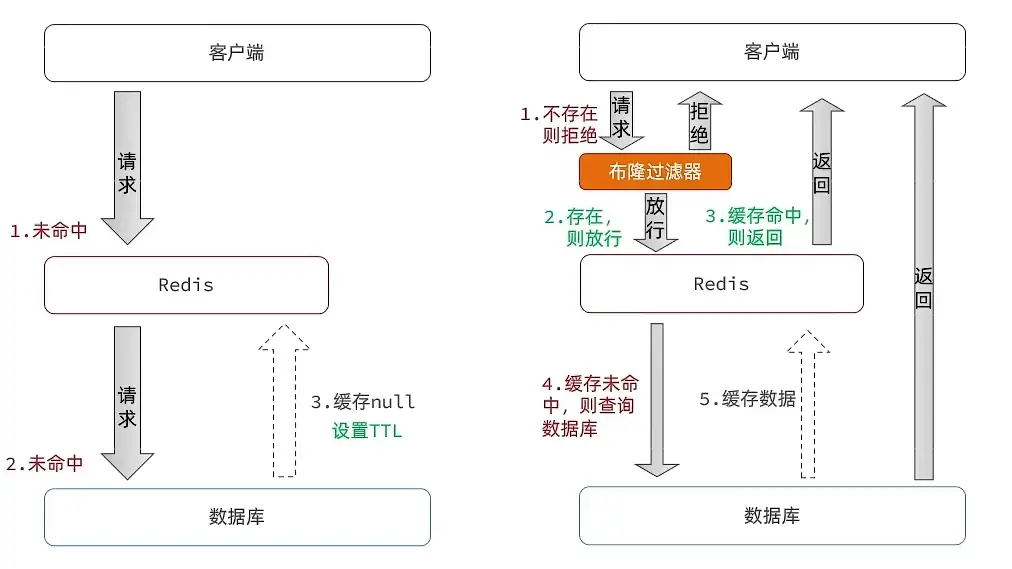
# 3.3 缓存穿透问题及解决思路
缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库,从而对数据库造成巨大压力。
方案一:缓存空对象 如果查询的这个数据在数据库中也不存在,我们也把这个空数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据
💡实现简单,维护方便,但会造成额外的内存消耗,以及可能造成短期的不一致
方案二:布隆过滤 布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,
💡内存占用较少,没有多余key,缺点是实现复杂,存在误判可能(哈希冲突)
# 3.4 缓存雪崩问题及解决思路
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
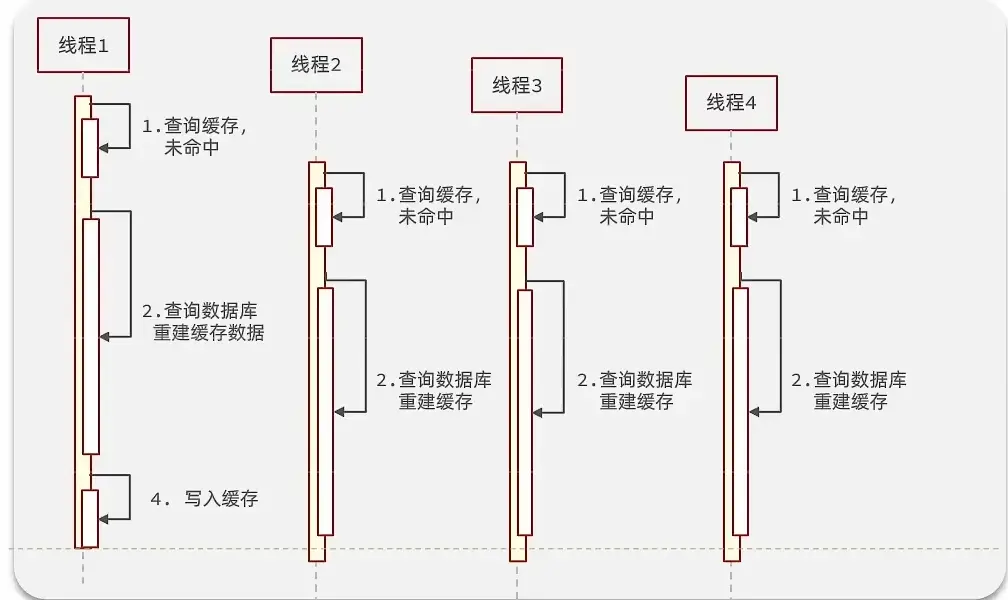
# 3.5 缓存击穿问题及解决思路
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
逻辑分析:假设线程1在查询缓存之后,本来应该去查询数据库,然后把这个数据重新加载到缓存的,此时只要线程1走完这个逻辑,其他线程就都能从缓存中加载这些数据了,但是假设在线程1没有走完的时候,后续的线程2,线程3,线程4同时过来访问当前这个方法, 那么这些线程都不能从缓存中查询到数据,那么他们就会同一时刻来访问查询缓存,都没查到,接着同一时间去访问数据库,同时的去执行数据库代码,对数据库访问压力过大
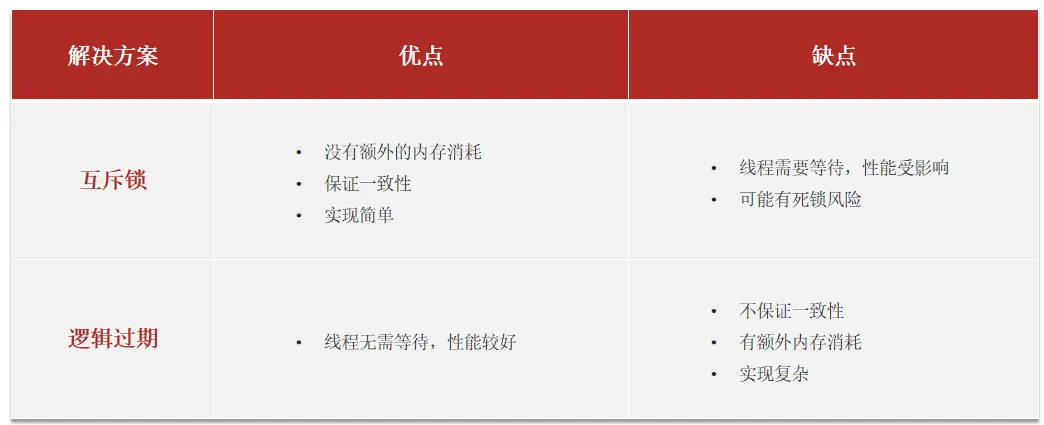
方案一:互斥锁方案 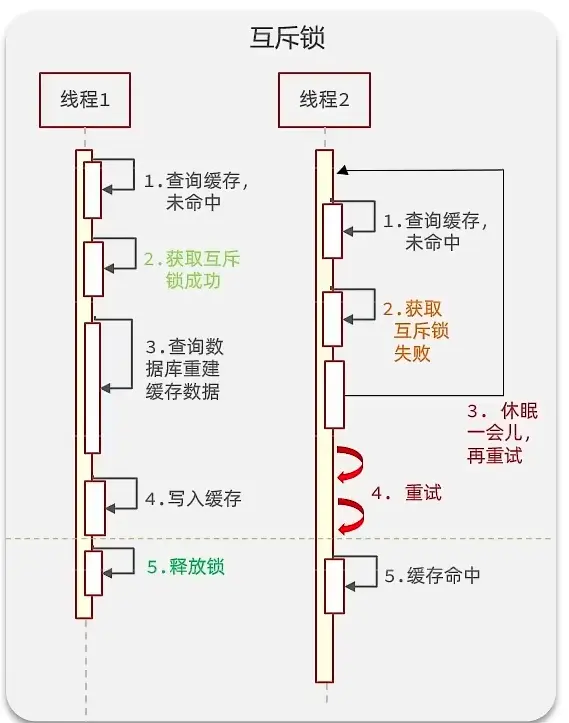
利用redis的setnx方法来表示获取锁
方案二:逻辑过期方案
方案分析:我们之所以会出现这个缓存击穿问题,主要原因是在于我们对key设置了过期时间,假设我们不设置过期时间,其实就不会有缓存击穿的问题,但是不设置过期时间,这样数据不就一直占用我们内存了吗,我们可以采用逻辑过期方案。
我们把过期时间设置在 redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程他会开启一个 线程去进行 以前的重构数据的逻辑,直到新开的线程完成这个逻辑后,才释放锁, 而线程1直接进行返回,假设现在线程3过来访问,由于线程线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,只有等到新开的线程2把重建数据构建完后,其他线程才能走返回正确的数据。
🔎这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据。
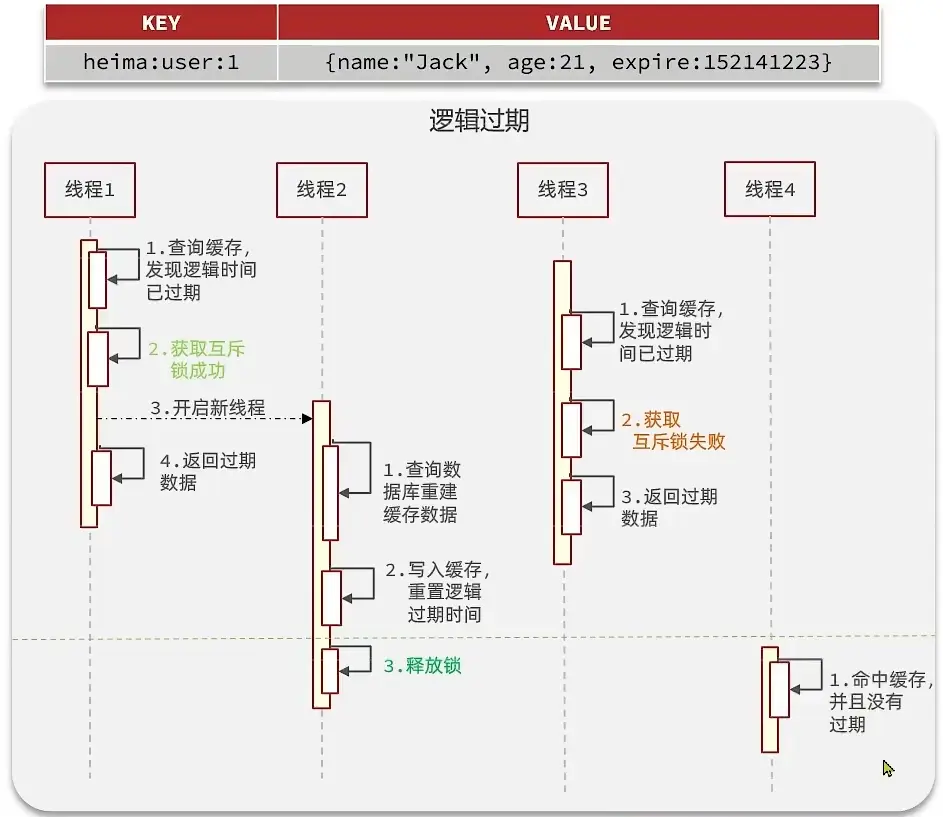
方案对比: