 Kafka篇
Kafka篇
Kafka是一种高吞吐量的分布式发布订阅消息系统
# 1. 基础架构
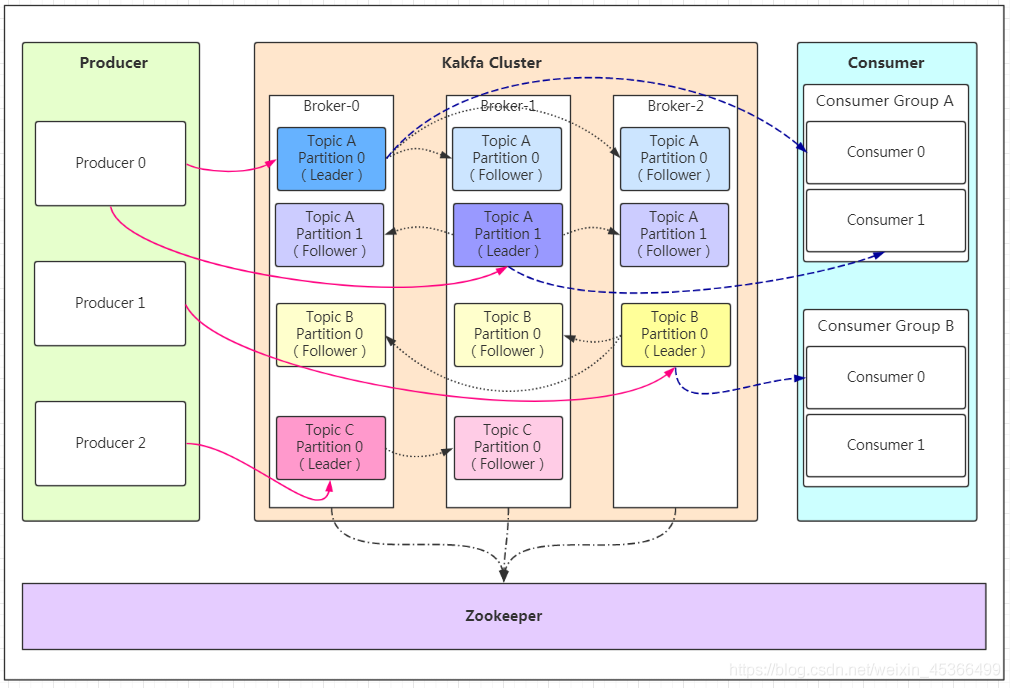
- Producer:消息的产生者
- Broker:Broker是kafka实例(每个实例可以视为一台服务器)
- Topic:消息的主题,可以理解为消息的分类,
- Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的
- Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。follower和leader绝对是在不同的机器,主分区提供读写功能
- Consumer:消费者
- Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
# 2. 数据发送
Kafka 的生产者在发送消息时,通过计算消息的分区号,并根据分区的 leader 副本信息(从zookeeper集群中获取)选择目标 broker 来发送消息,从而实现了消息的负载均衡和高可用性。
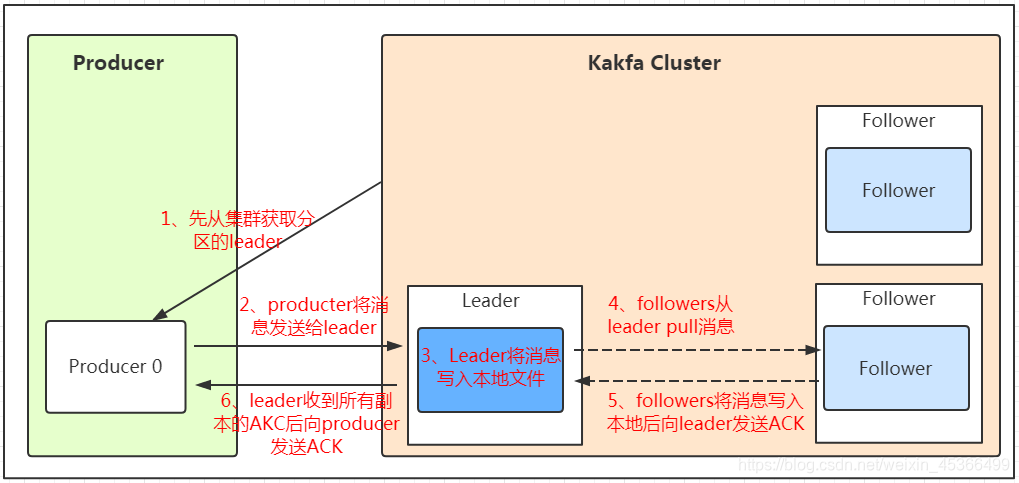
消息写入leader后,follower是主动的去leader进行同步的!producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!
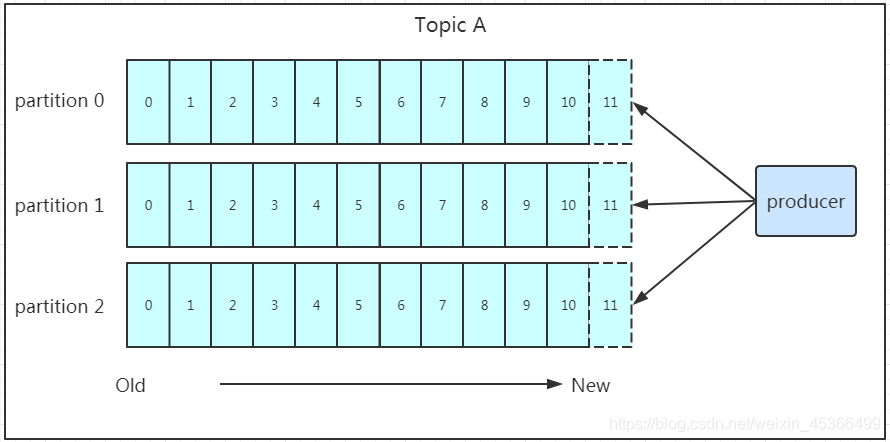
Q1: 为什么要进行数据分区?
- 方便扩展:因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
- 提高并发:以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
Q2: 如果某个topic有多个partition,producer又怎么知道该将数据发往哪个partition呢?
- partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
- 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
- 如果既没指定partition,又没有设置key,则会轮询选出一个partition。
Q3: producer在向kafka写入消息的时候,怎么保证消息不丢失呢?
通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据
# 3. 数据保存
kafka将数据保存在磁盘,Kafka初始会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)
每个topic都可以分为一个或多个partition,Partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件三个文件, log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息。

每个log文件的大小是一样的,但是存储的message数量是不一定相等的(每条的message大小不一致)。文件的命名是以该segment最小offset来命名的,如000.index存储offset为0~368795的消息,kafka就是利用分段+索引的方式来解决查找效率的问题。
# 4. 数据消费
多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id!同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会组内多个消费者消费同一分区的数据!!!
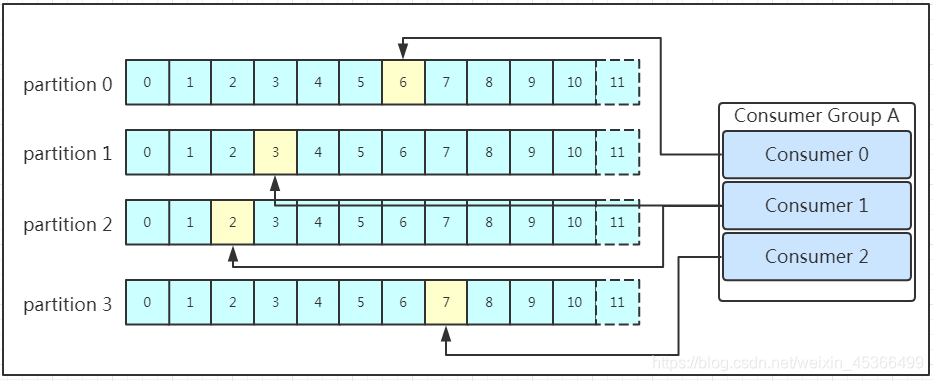
消费者将消费到的offset(黄色部分)维护zookeeper中,consumer每间隔一段时间上报一次,这里容易导致重复消费,且性能不好!在新的版本中消费者消费到的offset已经直接维护在kafk集群的__consumer_offsets这个topic中!
# 5. 集群管理
Kafka集群需要依赖Zookeeper作分布式协调,保存状态和实现选主。Kafka集群中会选出一个Broker来充当控制器(Controller),控制器负责管理分区和副本的状态以及执行管理任务,例如重新分配分区。最终这些数据保存在Zookeeper中称之为元数据(Metadata)
Zookeeper高可靠性适合做分布式协调,但是不太适合高并发的访问和大量的IO交互,以前客户端读取元数据,维护消息偏移量(Offset)都需要经过Zookeeper。而新版本Kafka为了减轻Zookeeper的负担将很多请求转移到了Broker上,客户端可以通过Broker获取所有Broker的地址、维护消息偏移量、访问其他元数据、创建Topic、分区、副本等等
# 6. 零拷贝技术的应用
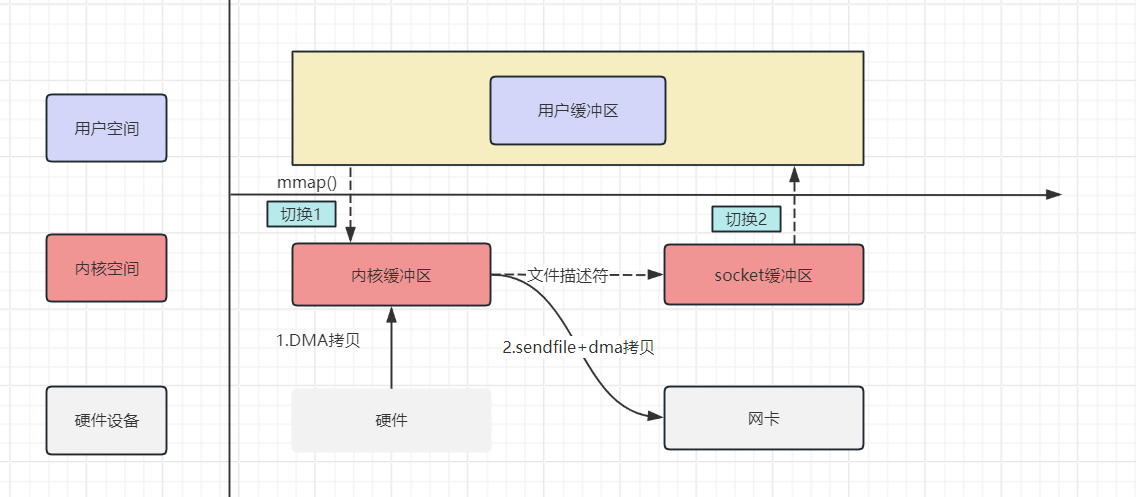
- 网络数据持久化到磁盘(Producer 到 Broker):Kafka使用mmap内存文件映射技术,将来自Producer的数据直接在OS内核缓冲区完成落盘
- 磁盘文件通过网络发送(Broker 到 Consumer):Kafka使用sendfile技术,可以直接将磁盘文件通过网络发送到Consumer,无需经过用户空间,减少了数据拷贝的次数