 Spring篇
Spring篇
# 1. Spring mvc处理一个请求的过程
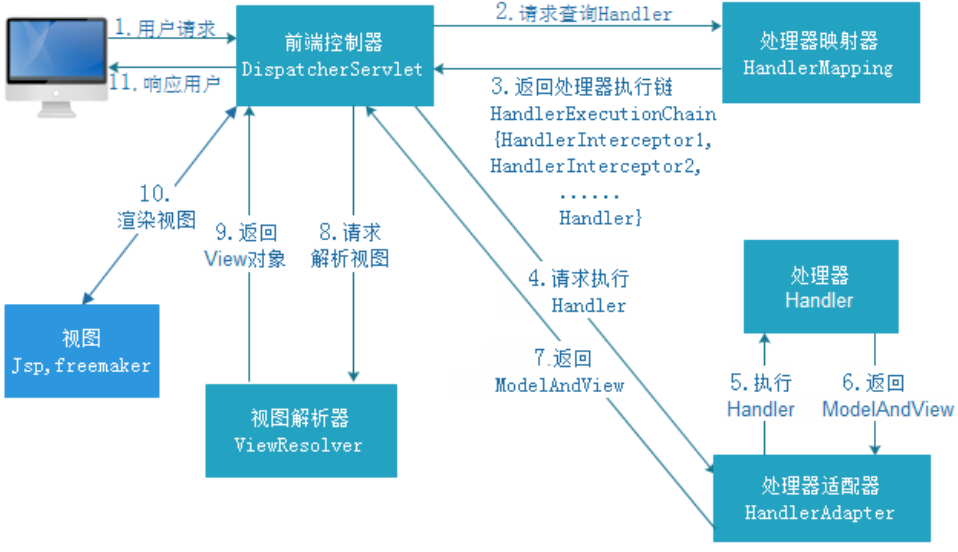
- 客户端浏览器将发出的请求封装为一个HttpServletRequest对象,转交请求给服务器
- 服务器收到请求后,转交请求给Web容器(Tomcat),Web容器调用Servlet处理请求。在Spring MVC中,这个Servlet就是前端控制器DispatcherServlet
- DispatcherServlet收到请求后,调用HandlerMapping处理器映射器。处理器映射器根据请求Url找到具体的Handler(后端控制器),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet
- DispatcherServlet调用HandlerAdapter处理器适配器去调用Handler。处理器适配器执行Handler,也就是执行我们的Controller层的业务逻辑。
- 最后,处理完业务逻辑后,返回ModelAndView对象,DispatcherServlet会将ModelAndView对象传给ViewResolver视图解析器进行解析,解析后返回对应的View
# 2. 过滤器和拦截器的区别
过滤器(Filter)和拦截器(Interceptor)都是基于AOP(面向切面编程)思想实现
- 实现机制:拦截器是基于Java的反射机制的,而过滤器是基于函数回调
- 依赖性:拦截器(Spring组件)不依赖于Servlet容器,而过滤器依赖于Servlet容器(只适用于web程序)
- 过滤器是在请求进入容器后,但请求进入servlet之前进行预处理的,所以filter的入参是RequestServlet。请求结束返回也是,是在servlet处理完后,返回给前端之前。如下图 而拦截器的入参是HttpRequestServlet
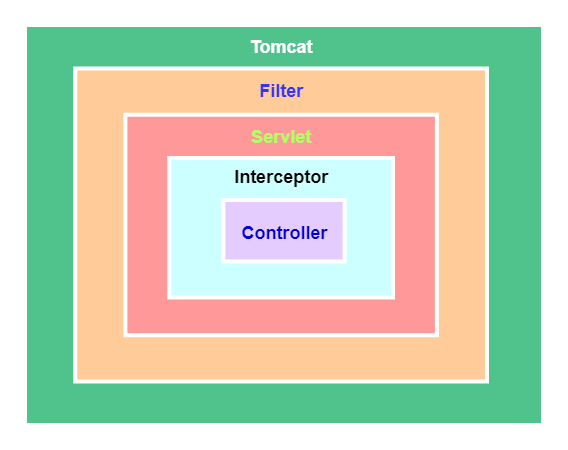
Web容器启动时,是先加载完所有的Bean,在进行监听器-》过滤器-》拦截器注册,所以都能获取到IOC容器中的Bean,也就是说可以在执行过程中调用业务逻辑
# 3. Concurrenthashmap如何实现互斥的?
Spring里常用的数据结构
ConcurrentHashMap是Java中的一个线程安全的HashMap,它允许多个线程并发访问哈希表,并发修改map中的数据而不会产生死锁。ConcurrentHashMap的互斥主要通过以下几种方式实现:
分段锁(Segment Locking):ConcurrentHashMap的对象被分为多个段,每个段都有自己的锁。这意味着多个线程可以同时更新ConcurrentHashMap,只要它们更新的是不同的段。这种机制提高了并发性,因为在更新时不需要锁定整个HashMap。
原子操作:ConcurrentHashMap提供了一些原子操作的方法,如putIfAbsent(), replace(), 和 remove()。这些方法可以确保在执行操作时不会被其他线程中断。
不允许使用null:ConcurrentHashMap不允许使用null作为键或值。这可以避免出现在多线程环境中的空指针异常。
# 4. Spring AOP原理
Spring的AOP(Aspect Oriented Programming,面向切面编程)是一种编程思想,是面向对象编程(OOP)的一种补充。AOP可以在不修改源代码的情况下给程序动态统一添加额外功能。Spring AOP的实现原理是基于动态代理和字节码操作的。在编译时,Spring会使用AspectJ编译器将切面代码编译成字节码文件。在运行时,Spring会使用Java动态代理或CGLIB代理生成代理类,这些代理类会在目标对象方法执行前后插入切面代码,从而实现AOP的功能
# 5. 线程池参数
corePoolSize:核心线程数。线程池维护的最小线程数量,即使这些线程处于空闲状态,他们也不会被销毁(注意:设置allowCoreThreadTimeout=true后,空闲的核心线程超过存活时间也会被回收)
maximumPoolSize:最大线程数。线程池允许创建的最大线程数量。当添加一个任务时,核心线程数已满,线程池还没达到最大线程数,并且没有空闲线程,工作队列已满的情况下,创建一个新线程并执行
keepAliveTime:空闲线程存活时间。当一个可被回收的线程的空闲时间大于keepAliveTime,就会被回收。可被回收的线程:设置allowCoreThreadTimeout=true的核心线程和大于核心线程数的线程(非核心线程)
unit:时间单位。keepAliveTime的时间单位
workQueue:工作队列。新任务被提交后,会先进入到此工作队列中,任务调度时再从队列中取出任务(由核心线程执行队列中的任务)
threadFactory:线程工厂。创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等
handler:拒绝策略。当工作队列中的任务已到达最大限制,并且线程池中的线程数量也达到最大限制,这时如果有新任务提交进来,该如何处理呢。这里的拒绝策略,就是解决这个问题的
# 5. 一致性哈希
一致性哈希(Consistent Hashing)
是一种用于分布式系统中数据分片的算法。它的主要目的是为了在系统扩容和缩容时最小化缓存数据的迁移量,从而减小系统的负载和影响,保证系统的高可用性。
一致性哈希的基本思想是将哈希值域组成一个虚拟的圆环,然后将数据映射到这个圆环上。节点的信息也被映射到这个圆环上。在查找数据的时候,先计算数据的哈希值并映射到圆环上,然后顺时针查找第一个节点,并将数据存储在这个节点上。
如果在这个节点发生故障时,可以通过顺时针查找的方式找到下一个节点并将数据存储在该节点上。因此,一致性哈希算法在节点变更时,只需要移动少量的数据即可完成数据迁移,从而大大减小了系统的负载和影响。
# 6. Spring和AOP的使用场景
Spring的IOC(Inversion of Control,控制反转)和AOP(Aspect Oriented Programming,面向切面编程)是两个核心的编程思想,它们在很多情况下都非常有用123。
IOC的使用场景:
- 解耦:IOC可以帮助我们将对象的创建和管理交给Spring容器,从而降低组件之间的耦合性,使得代码更加灵活和易于测试。
- 依赖注入:通过IOC,我们可以在运行时向某个对象提供它所依赖的其他对象。这使得我们的代码更加灵活,更容易进行单元测试。
- 生命周期管理:Spring IOC容器负责管理Bean的生命周期,包括创建、初始化、装配以及销毁等。
AOP的使用场景:
- 日志记录:可以在方法调用前后添加日志,以跟踪方法的执行情况。
- 事务管理:可以在需要执行数据库操作的方法周围添加事务管理代码,以确保数据的一致性和完整性。
- 权限验证:可以在方法调用前进行权限验证,以确保只有具有相应权限的用户才能调用该方法。
- 性能监测:可以在方法调用前后添加性能监测代码,以跟踪方法的执行时间,对系统性能进行优化。
- 缓存优化:对于查询操作,可以先从缓存中获取数据,如果缓存中没有,再从数据库中查询并将查询结果放入缓存。