 MySql进阶
MySql进阶
# 1. 多表查询
# 1.1 介绍
语法:select 字段列表 from 表1, 表2;
笛卡尔积:笛卡尔乘积是指在数学中,两个集合(A集合和B集合)的所有组合情况
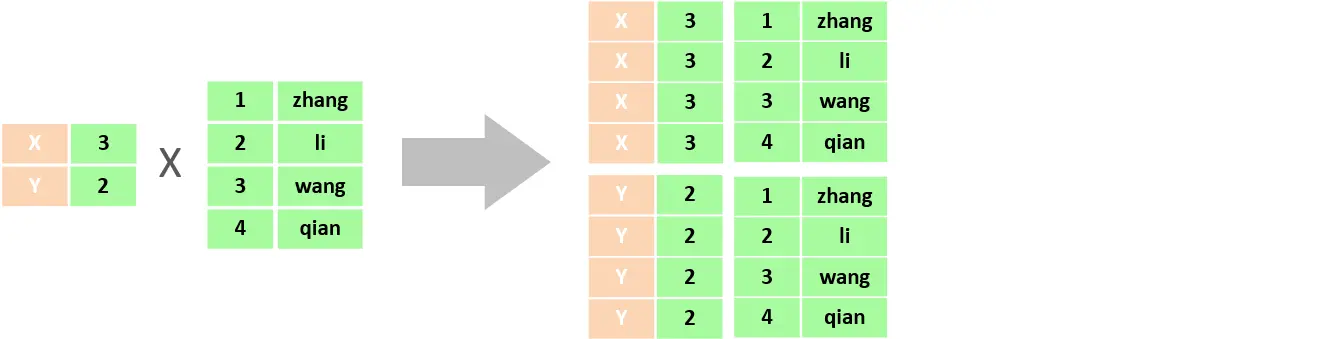
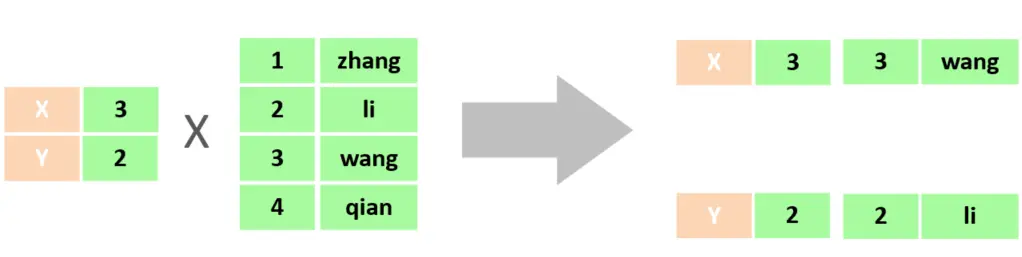
在多表查询时,需要消除无效的笛卡尔积,只保留表关联部分的数据 (使用where判断)
分类:
连接查询
- 内连接:相当于查询A、B交集部分数据
外连接
左外连接:查询左表所有数据(包括两张表交集部分数据)
右外连接:查询右表所有数据(包括两张表交集部分数据)
子查询
# 1.2 内连接
① 隐式内连接语法:
select 字段列表 from 表1 , 表2 where 条件 ... ;
② 显式内连接语法:
select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ;
# 1.3 外连接
① 左外连接语法结构(更偏向):
select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ;
② 右外连接语法结构:
select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ;
# 1.4 子查询
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... );
子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select
根据子查询结果的不同分为:
标量子查询(子查询结果为单个值[一行一列])
列子查询(子查询结果为一列,但可以是多行)
行子查询(子查询结果为一行,但可以是多列)
表子查询(子查询结果为多行多列[相当于子查询结果是一张表])
子查询可以书写的位置:
- where之后
- from之后
- select之后
# 2. 事务
提示
事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
# 2.1 操作
MYSQL中有两种方式进行事务的操作:
- 自动提交事务:即执行一条sql语句提交一次事务。(默认MySQL的事务是自动提交)
- 手动提交事务:先开启,再提交
| SQL语句 | 描述 |
|---|---|
| start transaction; / begin ; | 开启手动控制事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤:
- 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务
- 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
# 2.2 四大特性(ACID)
原子性(Atomicity) :原子性是指事务包装的一组sql是一个不可分割的工作单元,事务中的操作要么全部成功,要么全部失败。
一致性(Consistency):一个事务完成之后数据都必须处于一致性状态。 -- 如果事务成功的完成,那么数据库的所有变化将生效。 -- 如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。
隔离性(Isolation):多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
持久性(Durability):一个事务一旦被提交或回滚,它对数据库的改变将是永久性的,哪怕数据库发生异常,重启之后数据亦然存在。
# 2.3 Spring事务管理
@Transactional注解:就是在当前这个方法执行开始之前来开启事务,方法执行完毕之后提交事务。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作。
注解书写位置:
- service层方法
- 当前方法交给spring进行事务管理
- service层类
- 当前类中所有的方法都交由spring进行事务管理
- service层接口
- 接口下所有的实现类当中所有的方法都交给spring 进行事务管理
# 2.4 Spring事务进阶
描述@Transactional注解当中的两个常见的属性
# 2.4.1 异常回滚的属性:rollbackFor
PS: 默认情况下,只有出现RuntimeException(运行时异常)才会回滚事务。 作用:指定出现何种异常类型回滚事务。
@Transactional(rollbackFor=Exception.class)
# 2.4.2 事务传播行为:propagation
事务传播行为
就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制
| 属性值 | 含义 |
|---|---|
| REQUIRED | 【默认值】需要事务,已有则加入,无则创建新事务 |
| REQUIRES_NEW | 需要新事务,无论有无,总是创建新事务 |
| SUPPORTS | 支持事务,有则加入,无则在无事务状态中运行 |
| NOT_SUPPORTED | 不支持事务,在无事务状态下运行,如果当前存在已有事务,则挂起当前事务 |
| MANDATORY | 必须有事务,否则抛异常 |
| NEVER | 必须没事务,否则抛异常 |
| … |
@Transactional(propagation = Propagation.REQUIRES_NEW)
# 3. 索引
提示
帮助数据库高效获取数据的数据结构
# 3.1 介绍
优点:
- 提高数据查询的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点:
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
# 3.2 结构
提示
索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引
B+Tree(多路平衡搜索树)结构:
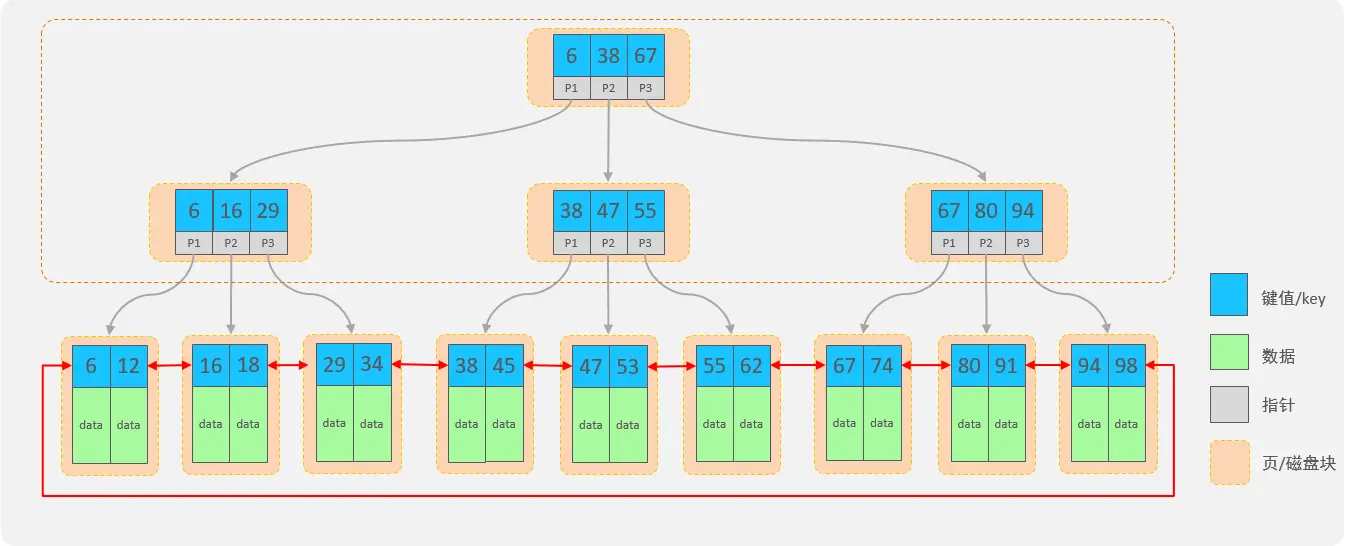
- 每一个节点,可以存储多个key(有n个key,就有n个指针)
- 节点分为:叶子节点、非叶子节点
- 叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
- 非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针
- 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
拓展:
非叶子节点都是由key+指针域组成的,一个key占8字节,一个指针占6字节,而一个节点总共容量是16KB,那么可以计算出一个节点可以存储的元素个数:16*1024字节 / (8+6)=1170个元素。
- 查看mysql索引节点大小:show global status like 'innodb_page_size'; -- 节点大小:16384
当根节点中可以存储1170个元素,那么根据每个元素的地址值又会找到下面的子节点,每个子节点也会存储1170个元素,那么第二层即第二次IO的时候就会找到数据大概是:1170*1170=135W。也就是说B+Tree数据结构中只需要经历两次磁盘IO就可以找到135W条数据。
对于第二层每个元素有指针,那么会找到第三层,第三层由key+数据组成,假设key+数据总大小是1KB,而每个节点一共能存储16KB,所以一个第三层一个节点大概可以存储16个元素(即16条记录)。那么结合第二层每个元素通过指针域找到第三层的节点,第二层一共是135W个元素,那么第三层总元素大小就是:135W*16结果就是2000W+的元素个数。
结合上述分析B+Tree有如下优点:
- 千万条数据,B+Tree可以控制在小于等于3的高度
- 所有的数据都存储在叶子节点上,并且底层已经实现了按照索引进行排序,还可以支持范围查询,叶子节点是一个双向链表,支持从小到大或者从大到小查找
# 3.3 语法
① 创建索引
create [ unique ] index 索引名 on 表名 (字段名,... ) ;
在创建表时,如果添加了主键和唯一约束,就会默认创建:主键索引、唯一约束
② 查看索引
show index from 表名;
③ 删除索引
drop index 索引名 on 表名;